Tại sao sử dụng bộ nhớ ảo (Virtual Memory) ?
Bộ nhớ ảo (Virtual Memory)
Nếu bạn là sinh viên chuyên ngành điện tử, chắc hẳn bạn sẽ phải làm quen với việc lập trình trên bộ vi điều khiển tại trường đại học.
Không giống như các hệ thống có hệ điều hành, bộ vi điều khiển hoạt động trực tiếp mà không có lớp trung gian hỗ trợ. Mỗi khi viết mã, bạn cần nạp chương trình vào bộ vi điều khiển thông qua các công cụ chuyên dụng (mạch nạp) để chương trình có thể thực thi.
Bên cạnh đó, CPU của bộ vi điều khiển thao tác trực tiếp trên các địa chỉ bộ nhớ vật lý, giúp việc truy cập và xử lý dữ liệu diễn ra nhanh chóng nhưng cũng đòi hỏi lập trình viên hiểu rõ về cấu trúc phần cứng.
Bạn không thể chạy hai chương trình cùng lúc trong trường hợp này. Giả sử cả hai chương trình đều cần sử dụng cùng một vị trí bộ nhớ, ví dụ địa chỉ 0x2000. Khi chương trình thứ hai ghi dữ liệu mới vào địa chỉ này, nó sẽ vô tình xóa dữ liệu mà chương trình đầu tiên đã lưu trước đó. Điều này khiến dữ liệu bị chồng chéo, gây lỗi và làm cả hai chương trình bị treo hoặc hoạt động sai.
Hệ điều hành đã giải quyết vấn đề này như thế nào ?
Vấn đề quan trọng ở đây là cả hai chương trình đều truy cập trực tiếp vào địa chỉ bộ nhớ vật lý tuyệt đối. Đây chính là điều cần tránh vì nó dễ gây ra xung đột dữ liệu khi nhiều chương trình cùng sử dụng một vùng nhớ.
Chúng ta có thể “cô lập” vùng nhớ mà mỗi chương trình sử dụng. Cụ thể, hệ điều hành sẽ cấp cho mỗi chương trình một vùng “địa chỉ ảo” riêng biệt. Nhờ đó, mỗi chương trình đều có không gian bộ nhớ riêng để “thoải mái sử dụng” mà không lo xung đột với chương trình khác. Tuy nhiên, để làm được điều này, có một điều kiện quan trọng: các chương trình không được phép truy cập trực tiếp vào địa chỉ bộ nhớ vật lý.
💡 Giải pháp: Hệ điều hành cung cấp cơ chế ánh xạ địa chỉ ảo sang địa chỉ vật lý.
Khi các chương trình chạy, mỗi chương trình sẽ sử dụng các địa chỉ ảo riêng biệt. Nếu một chương trình muốn truy cập địa chỉ ảo này, hệ điều hành sẽ tự động chuyển đổi nó thành một địa chỉ vật lý tương ứng trong bộ nhớ. Nhờ cơ chế này, các chương trình khác nhau sẽ ghi dữ liệu vào các địa chỉ vật lý khác nhau, tránh được xung đột dữ liệu khi chạy đồng thời.
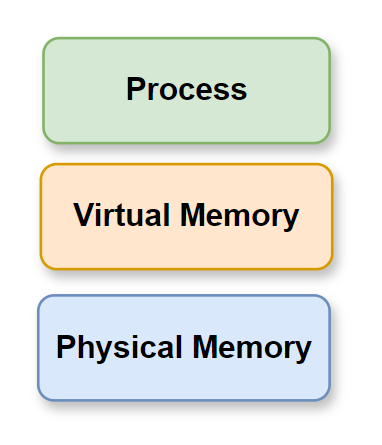
Vì vậy, có hai loại địa chỉ bộ nhớ quan trọng:
- Địa chỉ mà chương trình của chúng ta sử dụng được gọi là địa chỉ ảo (Virtual Address).
- Địa chỉ thực tế tồn tại trên phần cứng của máy tính được gọi là địa chỉ vật lý (Physical Address).
Hệ điều hành giới thiệu khái niệm bộ nhớ ảo và địa chỉ ảo.
Khi một chương trình muốn truy cập bộ nhớ, địa chỉ ảo mà nó sử dụng sẽ được chuyển đổi thành địa chỉ vật lý thông qua cơ chế ánh xạ của bộ quản lý bộ nhớ (MMU - Memory Management Unit) tích hợp trong chip CPU. Sau khi chuyển đổi, hệ thống sẽ truy cập bộ nhớ thực tế thông qua địa chỉ vật lý này. Quy trình này được minh họa trong hình sau:
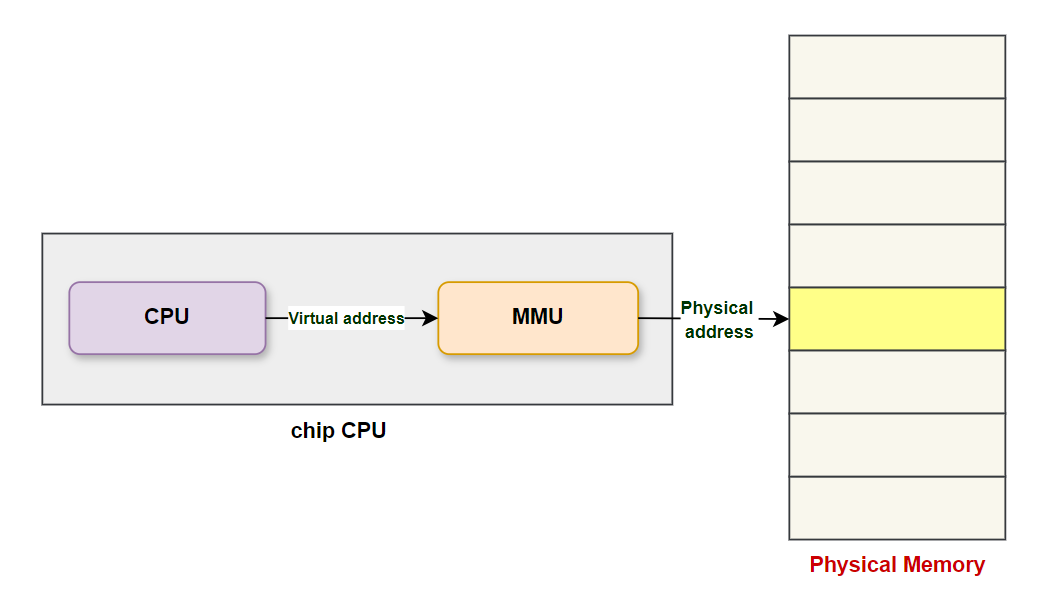
Hệ điều hành quản lý mối quan hệ giữa địa chỉ ảo và địa chỉ vật lý như thế nào?
Để thực hiện việc này, hệ điều hành sử dụng hai cơ chế chính: Phân đoạn bộ nhớ (Memory Segmentation) và Phân trang bộ nhớ (Memory Paging).
Trước tiên, chúng ta sẽ tìm hiểu về cơ chế phân đoạn bộ nhớ.
Phân đoạn bộ nhớ (Memory Segmentation)
Chương trình thường được chia thành các phân đoạn logic khác nhau, chẳng hạn như phân đoạn mã (code segment), phân đoạn dữ liệu (data segment), phân đoạn ngăn xếp (stack segment) và phân đoạn đống (heap segment). Mỗi phân đoạn có các đặc điểm và chức năng riêng biệt, vì vậy việc sử dụng phân đoạn giúp tách biệt và quản lý các thành phần này một cách hiệu quả.
Địa chỉ ảo và địa chỉ vật lý được ánh xạ như thế nào theo cơ chế phân đoạn ?
Địa chỉ ảo theo cơ chế phân đoạn gồm hai phần: hệ số lựa chọn phân đoạn (segment selector) và offset. Segment selector xác định phân đoạn cụ thể trong bộ nhớ, còn offset cho biết vị trí chính xác trong phân đoạn đó.
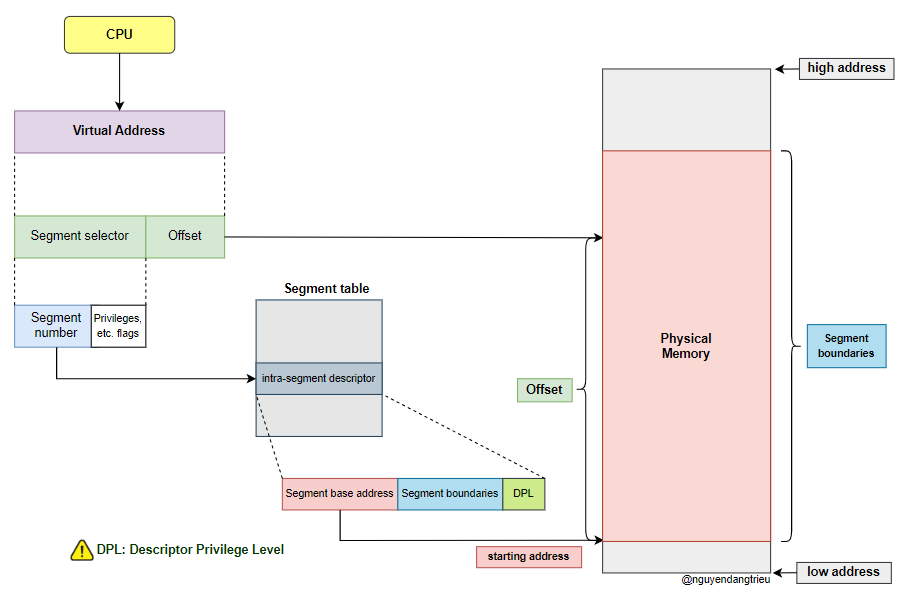
✅ Yếu tố lựa chọn phân đoạn và độ lệch trong phân đoạn
1️⃣ Segment Selector
- Được lưu trong thanh ghi phân đoạn (segment register).
- Thành phần quan trọng nhất của Segment Selector là số phân đoạn (segment number), dùng để tra cứu bảng phân đoạn - Segment Table.
- Segment Table chứa thông tin về phân đoạn, bao gồm:
- Segment Base Address - Điểm bắt đầu của phân đoạn trong bộ nhớ.
- Segment Boundaries - Giới hạn kích thước phân đoạn.
- Privilege Level (DPL) - Quyền truy cập vào phân đoạn.
2️⃣ Segment Offset
- Độ lệch (offset) là vị trí tương đối của dữ liệu bên trong phân đoạn. Giá trị offset phải nằm trong khoảng từ 0 -> Segment Boundaries.
- Nếu offset hợp lệ, địa chỉ vật lý được tính bằng:
📌Physical Address = Segment Base Address + Offset. - Nếu offset vượt quá giới hạn, hệ thống sẽ báo lỗi Segmentation Fault.
Ở trên, chúng ta biết rằng địa chỉ ảo được ánh xạ tới địa chỉ vật lý thông qua Segment Table. Cơ chế phân đoạn chia địa chỉ ảo của chương trình thành 4 segment. Mỗi segment có một mục tương ứng trong Segment Table. Mỗi mục trong Segment Table chứa Base Address của Segment. Khi một chương trình muốn truy cập vào một địa chỉ ảo, Base Address của segment được tìm trong bảng, sau đó cộng với offset để xác định địa chỉ thực tế trong bộ nhớ vật lý, như minh họa bên dưới:
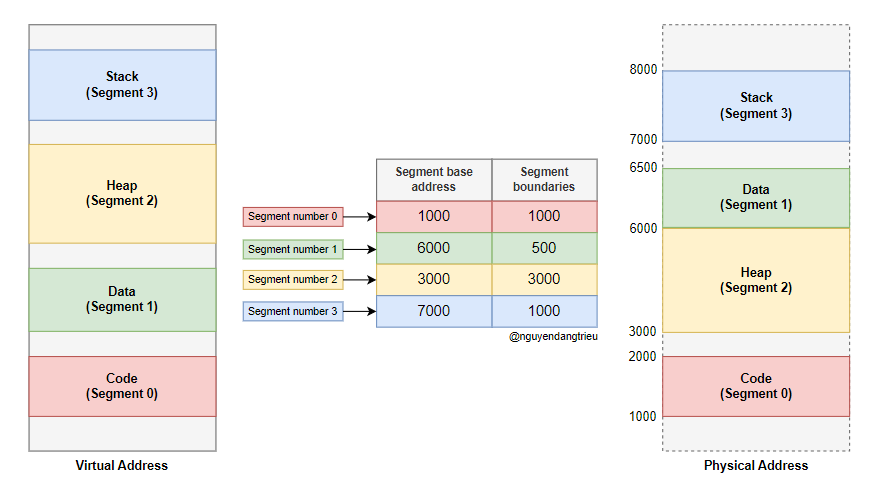
Nếu chúng ta muốn truy cập địa chỉ ảo tại vị trí offset = 500 trong segment 3, chúng ta có thể tính được: Physical Address = Base address + offset = 7000 + 500 = 7500
Phương pháp phân đoạn rất tốt, nó giải quyết được vấn đề là bản thân chương trình không cần quan tâm đến địa chỉ bộ nhớ vật lý cụ thể, nhưng nó cũng có một số nhược điểm ❌:
- 1️⃣ Phân mảnh bộ nhớ. (Memory Fragmentation)
- 2️⃣ Hiệu suất trao đổi bộ nhớ thấp.
Tiếp theo, ta hãy nói về lý do tại sao lại phát sinh hai vấn đề này.
Phân mảnh bộ nhớ (Memory Fragmentation)
Đọc thêm: Memory Fragmentation in operating system
Trước tiên, chúng ta hãy xem tại sao phân đoạn lại gây ra vấn đề phân mảnh bộ nhớ ❗
Hãy xem xét một ví dụ như này. Giả sử ta có 1 GB bộ nhớ vật lý và người dùng - user thực hiện nhiều chương trình trên bộ nhớ đó:
- Game chiếm
512 MB. - Trình duyệt WEB chiếm
128 MB. - Music chiếm
256 MB.
Lúc này nếu ta đóng trình duyệt WEB đi thì bộ nhớ vật lý sẽ trong như thế này: 1024 - 512 - 256 = 256 MB vùng nhớ trống còn lại.
Nếu 256 MB vùng nhớ này không nằm liên tục và được chia thành 2 phân đoạn, mỗi phân đoạn là 128 MB. Vấn đề phát sinh đó là nếu ta muốn mở 1 chương trình 200 MB thì sẽ không cấp phát đủ vùng nhớ, dù tổng bộ nhớ trống là 256 MB.
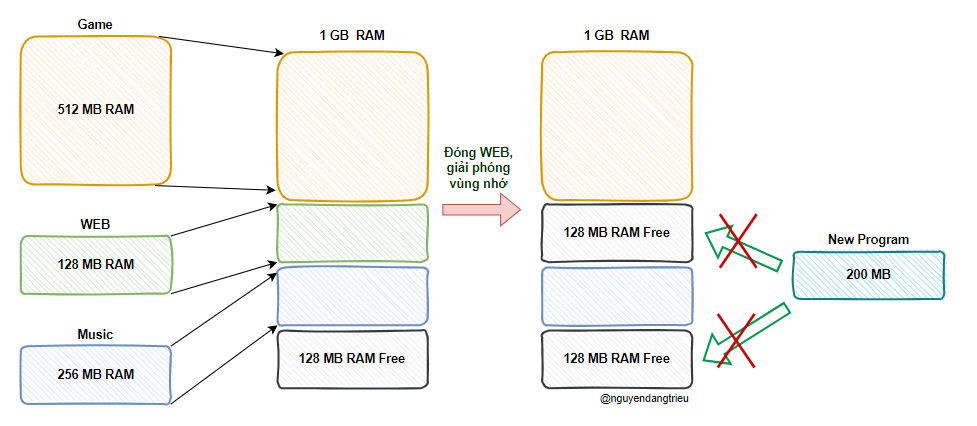
Liệu sự phân mảnh bộ nhớ có xảy ra do phân đoạn bộ nhớ không?
Phân mảnh bộ nhớ chủ yếu được chia thành phân mảnh bộ nhớ trong và phân mảnh bộ nhớ ngoài.
- Quản lý phân đoạn bộ nhớ cho phép phân bổ bộ nhớ cho các phân đoạn dựa trên nhu cầu thực tế, do đó kích thước của từng phân đoạn sẽ thay đổi theo yêu cầu. Điều này giúp tránh tình trạng phân mảnh bộ nhớ trong.
- Tuy nhiên, do độ dài của mỗi phân đoạn không cố định, có thể xảy ra tình trạng nhiều phân đoạn không sử dụng hết không gian bộ nhớ. Điều này khiến bộ nhớ trống bị phân tán thành các khối nhỏ không liên tiếp, tạo ra phân mảnh bộ nhớ ngoài, làm cho việc tải chương trình mới trở nên khó khăn hoặc không thể thực hiện được.
Giải pháp cho vấn đề phân mảnh bộ nhớ ngoài là hoán đổi bộ nhớ (Swapping).
Khi gặp vấn đề phân mảnh bộ nhớ ngoài, một giải pháp là hoán đổi vùng nhớ mà chương trình đang sử dụng. Ví dụ: ta sẽ ghi (swap out) 256MB vùng nhớ mà chương trình Music đang chiếm dụng vào ổ cứng (disk). Lúc này, vùng nhớ trống sẽ là 512 MB liền kề nhau.
Sau đó, khi cần, ta sẽ đọc ngược lại (swap in) dữ liệu từ disk vào lại bộ nhớ. Khi đó, bộ nhớ trống sẽ là 256 MB liên tục, đủ để tải chương trình 200 MB mà người dùng yêu cầu.
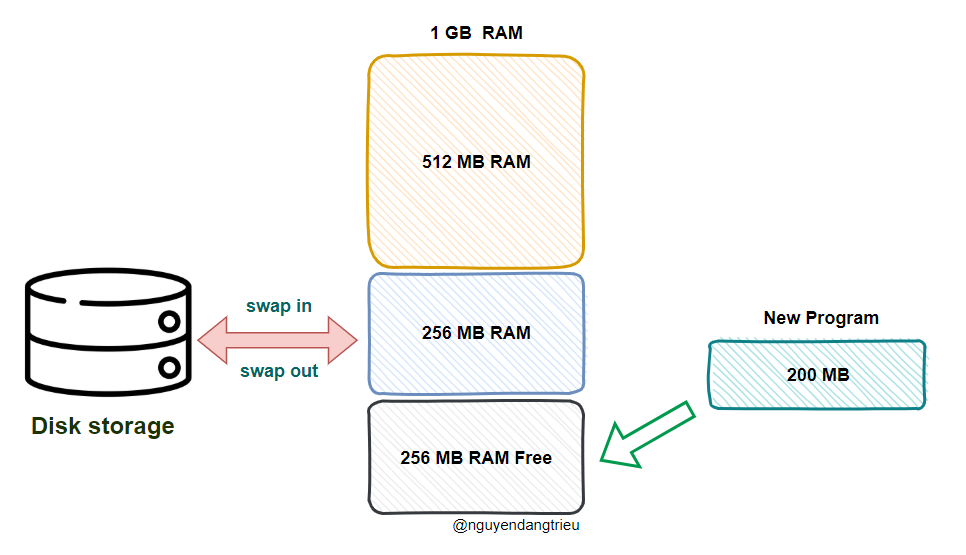
Không gian hoán đổi bộ nhớ này, trong các hệ thống như Linux, được gọi là swap space. Đây là không gian trên ổ cứng, tách biệt với bộ nhớ chính, dùng để hoán đổi giữa bộ nhớ vật lý và bộ nhớ ảo.
Hiệu suất
Chúng ta hãy xem “Tại sao phân đoạn lại dẫn đến hiệu quả hoán đổi bộ nhớ thấp❓”
Trong hệ thống đa tiến trình, bộ nhớ có thể bị phân mảnh ngoài khi sử dụng phân đoạn. Khi điều này xảy ra, hệ thống phải hoán đổi (swap) dữ liệu giữa RAM và ổ cứng, làm giảm hiệu suất do tốc độ truy cập ổ cứng chậm hơn nhiều so với RAM.
Nếu một chương trình chiếm nhiều bộ nhớ bị hoán đổi, toàn bộ hệ thống có thể bị chậm hoặc “đơ”.
💡 Để giải quyết vấn đề “phân mảnh bộ nhớ ngoài và hiệu suất hoán đổi bộ nhớ thấp” của phân đoạn bộ nhớ, phân trang bộ nhớ đã xuất hiện.
Phân trang bộ nhớ (Memory Paging)
Ưu điểm của phân đoạn là nó cung cấp không gian bộ nhớ liên tục cho chương trình. Tuy nhiên, nó cũng gây ra vấn đề như phân mảnh bộ nhớ ngoài và không gian hoán đổi quá lớn.
Để khắc phục, chúng ta cần giảm phân mảnh bộ nhớ và tối ưu hóa quá trình hoán đổi. Nếu lượng dữ liệu cần hoán đổi hoặc tải từ ổ đĩa ít hơn, hiệu suất hệ thống sẽ được cải thiện. Giải pháp cho vấn đề này là phân trang bộ nhớ - Memory Paging.
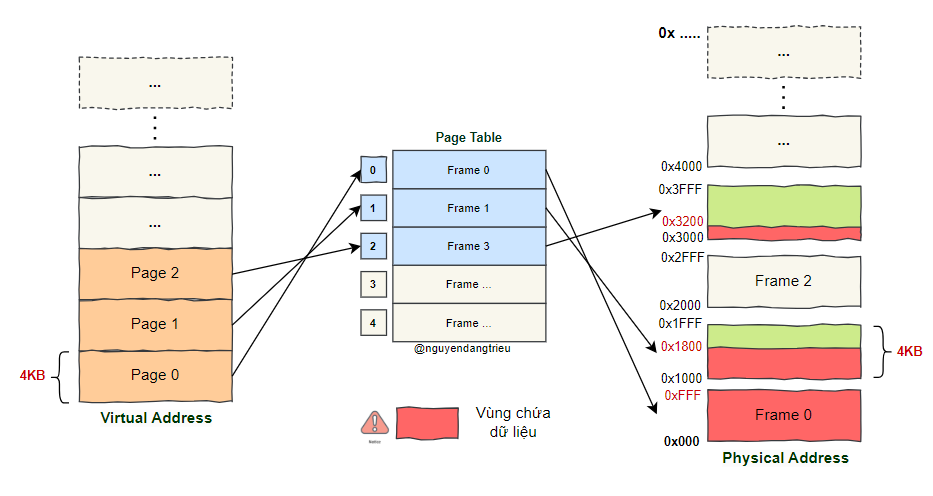
Phân trang là quá trình chia bộ nhớ ảo và bộ nhớ vật lý thành các khối nhỏ có kích thước cố định. Mỗi khối có không gian bộ nhớ liên tục và kích thước cố định này được gọi là trang (page). Trên Linux, kích thước mặc định của mỗi trang là 4 KB.
Địa chỉ ảo và địa chỉ vật lý được ánh xạ thông qua bảng trang - Page Table, như được hiển thị bên dưới:
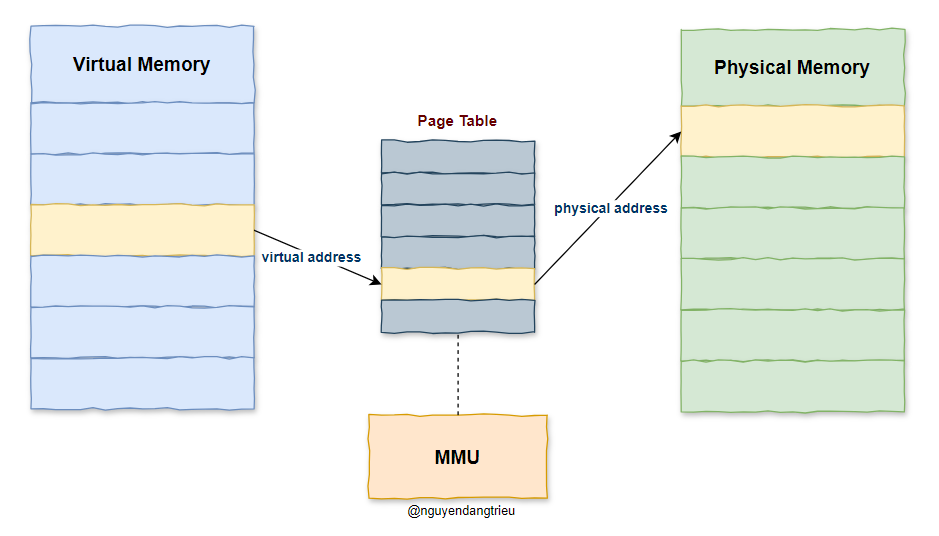
Bảng trang được lưu trữ trong bộ nhớ và đơn vị quản lý bộ nhớ (MMU) có nhiệm vụ chuyển đổi địa chỉ bộ nhớ ảo thành địa chỉ vật lý.
Khi một tiến trình truy cập một địa chỉ ảo không có trong bảng trang, hệ thống sẽ kích hoạt một lỗi trang (Page Fault). Lúc này, quyền điều khiển sẽ được chuyển vào không gian hạt nhân để xử lý. Hệ thống sẽ cấp phát một khung trang trong bộ nhớ vật lý, cập nhật bảng trang của tiến trình, rồi quay lại không gian người dùng để tiếp tục thực thi tiến trình đó.
Phân trang giải quyết vấn đề “phân mảnh bộ nhớ ngoài và hiệu suất hoán đổi bộ nhớ thấp” của phân đoạn như thế nào❓
Trong phân trang bộ nhớ, không gian bộ nhớ được chia thành các trang có kích thước cố định ngay từ đầu, giúp loại bỏ các khoảng trống nhỏ giữa các phân đoạn như trong phân đoạn bộ nhớ. Đây chính là nguyên nhân khiến phân đoạn gây ra phân mảnh bộ nhớ ngoài. Ngược lại, với phân trang các trang được sắp xếp liên tục và chặt chẽ, do đó không xảy ra phân mảnh bên ngoài.
Tuy nhiên, do đơn vị cấp phát bộ nhớ tối thiểu trong phân trang là một trang, nên ngay cả khi một chương trình có kích thước nhỏ hơn một trang, hệ thống vẫn phải cấp phát toàn bộ một trang. Điều này dẫn đến lãng phí bộ nhớ bên trong trang, gây ra hiện tượng phân mảnh bộ nhớ trong trong cơ chế phân trang.
Khi bộ nhớ không đủ, hệ điều hành sẽ giải phóng các trang không được sử dụng gần đây từ các tiến trình khác bằng cách ghi tạm thời chúng vào ổ cứng, quá trình này gọi là Swap Out. Khi cần, các trang này sẽ được nạp lại vào bộ nhớ, gọi là Swap In. Nhờ vậy, hệ thống chỉ hoán đổi một số trang thay vì toàn bộ tiến trình, giúp giảm thời gian ghi/đọc đĩa và tăng hiệu suất hoán đổi bộ nhớ.
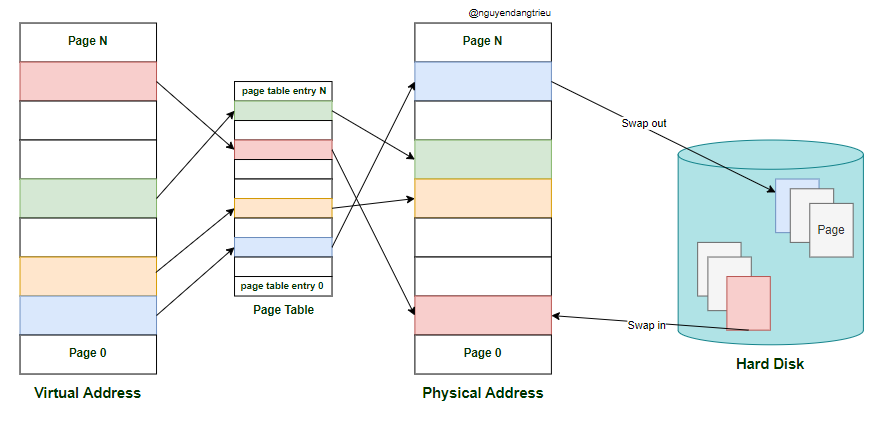
Phương pháp phân trang cho phép chúng ta không phải tải toàn bộ chương trình vào bộ nhớ vật lý cùng một lúc. Thay vào đó, chúng ta có thể ánh xạ các trang giữa bộ nhớ ảo và bộ nhớ vật lý mà không cần phải tải chúng ngay lập tức. Chỉ khi chương trình cần truy cập các lệnh hoặc dữ liệu trong những trang bộ nhớ ảo tương ứng, thì hệ thống mới tải các trang đó vào bộ nhớ vật lý.
2. Địa chỉ ảo và địa chỉ vật lý được ánh xạ như thế nào theo cơ chế phân trang?
Trước hết ta sẽ tìm hiểu 2 khái niệm đó là địa chỉ ảo và địa chỉ vật lý.
- Virtual Address: gồm 2 phần đó là number page và offset page
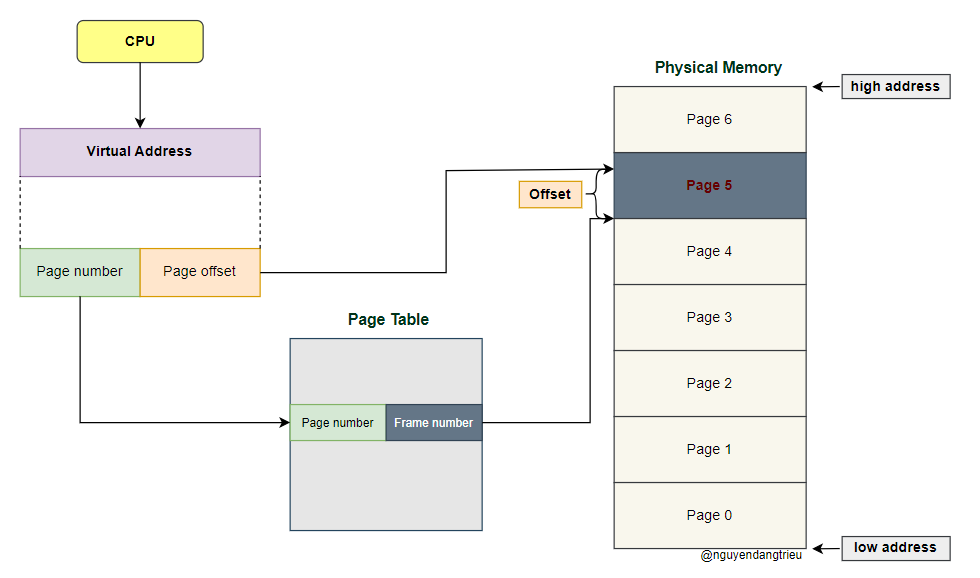
- Page number: Xác định số page trong không gian địa chỉ ảo. Hệ điều hành dùng phần này để tra Page Table và tìm địa chỉ vật lý tương ứng.
- Page offset: Xác định vị trí cụ thể (byte) trong page mà CPU muốn đọc hoặc ghi.
📌 Virtual Address = page number + page offset
- Physical Address: gồm 2 phần đó là frame number và page offset
- Frame number: Xác định frame chính xác trong bộ nhớ vật lý mà dữ liệu thực tế đang được lưu trữ.
- Page offset: Cho biết vị trí chính xác trong page mà CPU muốn đọc. Phần này không cần dịch vì kích thước page và kích thước frame là như nhau, nên vị trí của dữ liệu mà CPU muốn truy cập sẽ không thay đổi.
📌 **Physical Address = frame number + page offset
Quá trình ánh xạ diễn ra như sau: CPU tạo ra địa chỉ ảo, gồm page number và page offset. Thanh ghi PTBR (Page Table Base Register) chứa địa chỉ của bảng trang - Page Table, bảng này giúp ánh xạ Page number thành Frame number trong bộ nhớ vật lý. Sau khi tìm được Frame number, kết hợp với Page offset, ta xác định được địa chỉ vật lý và truy cập page trong bộ nhớ chính.
✏️ Ví dụ: Bạn có một cuốn sách gồm 10 trang, mỗi trang có 10 dòng. Bây giờ, bạn muốn đọc dữ liệu tại dòng 5 của trang 3.
- Đầu tiên, bạn mở sách và lật đến trang số 3 (tương ứng với Page number).
- Sau đó, bạn di chuyển mắt xuống dòng thứ 5 trên trang đó (tương ứng với Page offset) để lấy thông tin.
Trong hệ thống bộ nhớ, CPU cũng làm điều tương tự
- CPU sử dụng Page number để tìm trang dữ liệu trong không gian địa chỉ ảo.
- Hệ điều hành ánh xạ Page đó vào Frame number trong bộ nhớ vật lý. Sau đó, Page offset giúp xác định vị trí chính xác trong Frame để lấy dữ liệu.
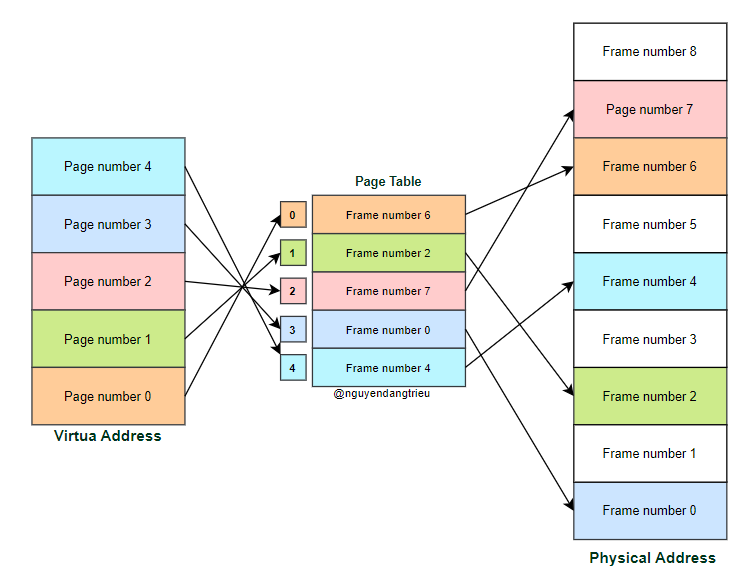
Dưới đây là một ví dụ về cách mà một Page trong bộ nhớ ảo ánh xạ tới một Frame trong bộ nhớ vật lý.
Việc sử dụng phân trang có vẻ tốt, nhưng trong các hệ điều hành thực tế, việc chỉ dùng phân trang đơn cấp (Single-Level Page Table) như này sẽ gây ra vấn đề.
Có vấn đề nào xảy ra khi sử dụng Single-Level Page Table không❓
Vấn đề về bộ nhớ
Hệ điều hành có thể chạy nhiều tiến trình cùng lúc, điều này có nghĩa là bảng trang của mỗi tiến trình sẽ rất lớn.
Trong hệ thống 32-bit, không gian địa chỉ ảo tối đa là 4GB.
- Giả sử kích thước của mỗi page là
4KB. - Như vậy, số lượng page cần quản lý sẽ là:
4GB/4KB= 1 048 576 (hay khoảng 2^20 page) - Mỗi Entry trong Page Table cần
4 byteđể lưu trữ thông tin ánh xạ. - Tổng dung lượng cần để lưu Page Table của một tiến trình là: 1 048 576 ×
4B=4MB
Một Page Table 4MB có vẻ không quá lớn, nhưng mỗi tiến trình trong hệ điều hành đều có Page Table riêng, vì mỗi tiến trình có không gian địa chỉ ảo riêng.
✏️ Ví dụ: Nếu có 100 process đang chạy đồng thời, thì tổng dung lượng dành riêng cho Page Table cho tất cả các process sẽ là: 100 × 4MB = 400MB. Khi dùng 400MB chỉ để lưu Page Table là một con số rất lớn, đặc biệt đối với hệ thống có RAM hạn chế. Chưa kể trong hệ thống 64-bit, số lượng Page còn nhiều hơn, khiến vấn đề càng trở nên nghiêm trọng hơn.
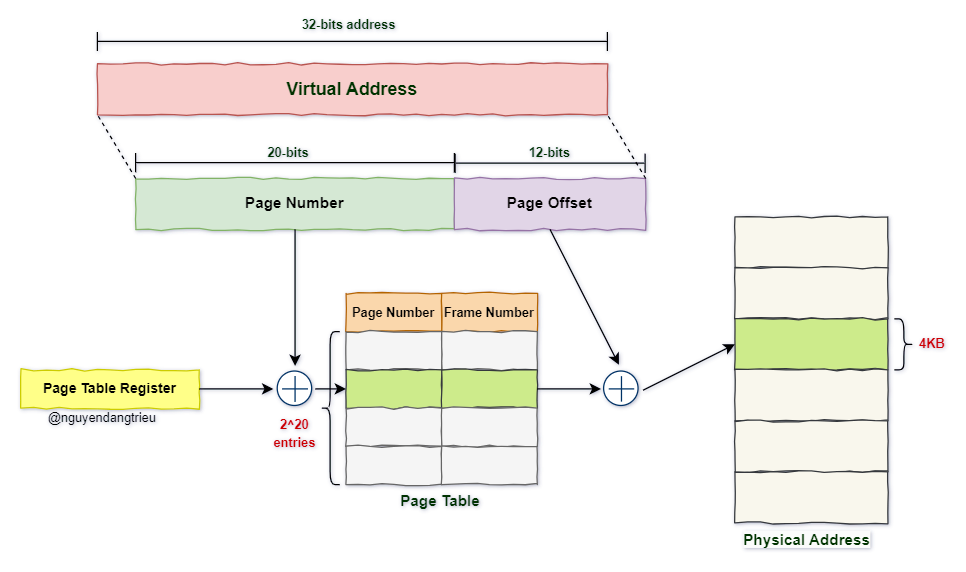
🔹 Câu hỏi đặt ra là: “Tại sao Page Offset là 12 bits ❓”
Trong hệ thống 32-bit, kích thước của Frame quyết định số bit dùng cho Page Offset.
- Với Frame =
4KB= 4096 byte, ta cần 12 bit để đánh địa chỉ từng byte trong Frame. Những byte này sẽ được phân bố đều trong 4096 địa chỉ vật lý liên tiếp. - Để truy cập một byte dữ liệu trong Frame, ta sử dụng Page Offset để xác định vị trí chính xác của byte đó.
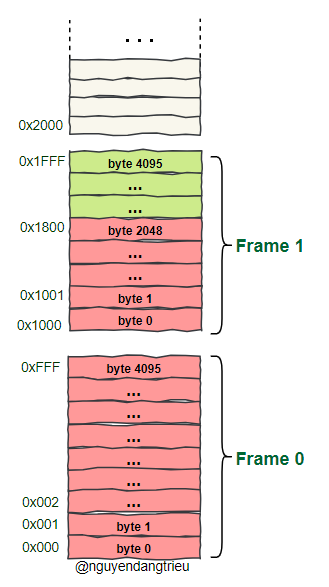
Với hình bên trên thì
- Page Offset của Frame 0 = 0xfff (12-bits)
- Page Offset của Frame 1 = 0x800 (12-bits)
- Page Offset của Frame 3 = 0x200 (12-bits)
Multi-Level Page Table
💡 Để có thể giải quyết vấn đề trên, ta dùng giải pháp gọi là bảng trang đa cấp (Multi-Level Page Table).
Như đã biết, trong hệ thống 32-bit với kích thước page là 4KB, một Single-Level Page Table cần chứa 1 048 576 Entry. Mỗi Entry chiếm 4 byte, nghĩa là toàn bộ Page Table sẽ tiêu tốn 4MB bộ nhớ. Điều này gây lãng phí lớn, đặc biệt khi không phải toàn bộ không gian địa chỉ đều được sử dụng.
Để tối ưu, ta chia Single-Level Page Table thành Multi-Level Page Table. Cụ thể, thay vì một Page Table lớn với 1 048 576 entries, ta chia nó thành 2 bảng trang:
- Bảng trang cấp 1 gọi là Page Directory. Mỗi entry trong Page Directory sẽ trỏ tới 1 Page Table
- Bảng trang cấp 2 được gọi là Page Table. Mỗi entry trong Page Table được gọi là Page Table Entry (PTE) và trỏ đến một frame trong bộ nhớ vật lý.
Thay vì phải lưu toàn bộ bảng trang 4MB trong bộ nhớ khi sử dụng Single-Level Page Table, với Multi-Level Page Table, ta chỉ cần cấp phát các bảng trang cấp hai “khi cần thiết”. Điều này giúp tiết kiệm bộ nhớ đáng kể, đặc biệt khi chỉ một phần nhỏ của không gian địa chỉ được sử dụng thực tế.
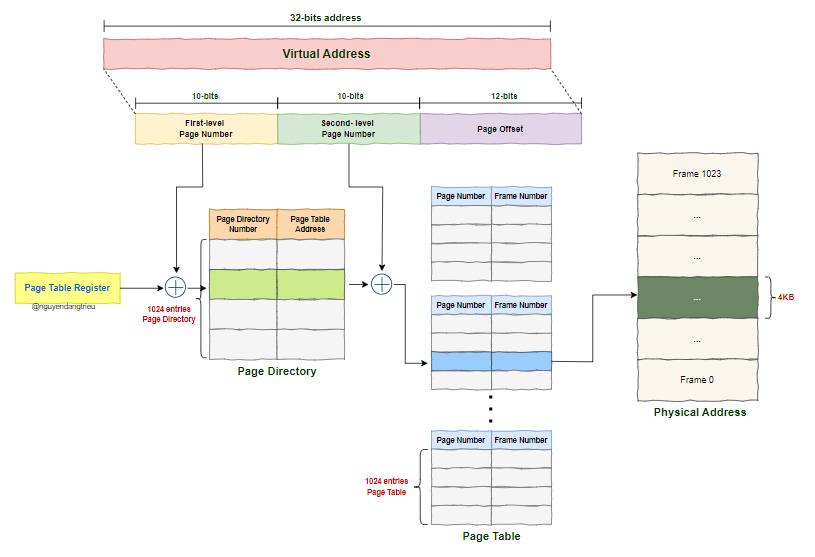
📌 Dung lượng bộ nhớ cần để ánh xạ toàn bộ không gian địa chỉ ảo 4GB bằng Multi-Level Page Table:
- Page Directory có kích thước
4KB, gồm 1024 entries (mỗi entry 4 byte), mỗi entry trỏ đến một Page Table. - Mỗi Page Table có 1024 entries, quản lý
4MBkhông gian địa chỉ (mỗi entry trỏ đến một Frame có kích thước4KB). - Để ánh xạ toàn bộ
4GBkhông gian địa chỉ, cần 1024 Page Tables. - Mỗi Page Table chiếm
4KB, vậy tổng bộ nhớ cần cho tất cả Page Tables là1024 × 4KB = 4MB.
Nếu sử dụng Multi-Level Page Table. Thì việc ánh xạ không gian địa chỉ 4GB sẽ cần 4KB (bảng trang cấp một) + 4MB (bảng trang cấp hai). Như vậy, có phải sẽ tốn nhiều bộ nhớ hơn không ❓
Ở đây ta phải biết rằng Single-level Page Table dùng 4MB để quản lí Page Table, còn Multi-Level Page Table dùng 4KB + 4MB để có thể quản lí Page Table.
Tất nhiên, nếu toàn bộ 4GB không gian địa chỉ ảo được ánh xạ vào bộ nhớ vật lý, thì Multi-Level Page Table sẽ chiếm nhiều bộ nhớ. Tuy nhiên, trong thực tế, một tiến trình thường không cần toàn bộ 4GB bộ nhớ.
Chúng ta có thể nhìn vấn đề từ một góc độ khác. Bạn có biết Locality of Reference không? 🤔🤔🤔
Mỗi tiến trình có không gian địa chỉ ảo 4GB, nhưng hầu hết chương trình chỉ sử dụng một phần nhỏ. Vì vậy, nhiều entry trong Page Table sẽ không được cấp phát. Đối với các entry của Page Table đã được cấp phát, nếu không được truy cập trong một thời gian dài, hệ điều hành có thể hoán đổi trang (swap in & out) ra ổ cứng để tiết kiệm bộ nhớ vật lý.
Với Multi-Level Page Table:
- Bảng trang cấp một (Page Directory) có thể bao phủ toàn bộ không gian địa chỉ ảo
4GB. - Tuy nhiên, nếu một mục nhập của bảng trang cấp một không được sử dụng, thì không cần tạo bảng trang cấp hai tương ứng -> nghĩa là bảng trang cấp hai chỉ được tạo khi cần thiết.
✏️ Ví dụ: Giả sử chỉ 20% các entry của Page Directory được sử dụng, thì tổng bộ nhớ cấp phát để lưu trữ các Page Table sẽ là:
- Page Directory có kích thước cố định là
4KB. - Chỉ dùng 20% các entry -> có 205 Page Table được cấp phát, mỗi Page Table chiếm
4KB=> Tổng dung lượng Page Table = 205 *4KB=820KB.
👉 Tổng không gian do Page chiếm dụng là: 4KB + 820KB = 0.804MB. So với 4MB trong phân trang một cấp, đây là một mức tiết kiệm đáng kể.
Vậy tại sao một bảng trang không phân cấp lại không thể tiết kiệm bộ nhớ như thế này❓
Bản chất của bảng trang cho thấy rằng nó được lưu trữ trong bộ nhớ và có nhiệm vụ dịch địa chỉ ảo thành địa chỉ vật lý. Nếu một địa chỉ ảo không tìm thấy mục tương ứng trong bảng trang, hệ thống máy tính sẽ không thể hoạt động bình thường. Do đó, bảng trang cần phải bao phủ toàn bộ không gian địa chỉ ảo.
Trong một hệ thống không có phân trang cấp hai, bảng trang cần hơn 1 triệu mục để ánh xạ toàn bộ không gian địa chỉ ảo. Tuy nhiên, với phân trang hai cấp, chỉ cần 1024 mục trong Page Directory, và các Page Table chỉ được tạo ra khi cần thiết. Điều này giúp tiết kiệm bộ nhớ hơn.
Nếu tiếp tục mở rộng lên phân trang nhiều cấp, chúng ta sẽ giảm đáng kể dung lượng bộ nhớ cần thiết để lưu bảng trang. Đây là một ứng dụng hiệu quả của Locality of Reference.
(Còn nữa)