Linux IO

Mở đầu
Đối với một ứng dụng (hay một tiến trình trong hệ điều hành), không gian bộ nhớ được chia thành 2 phần:
- Không gian hạt nhân (Kernel-space): được chia sẽ với các tiến trình khác.
- Không gian người dùng (User-space): riêng đối với mỗi tiến trình.
Cả hai đều nằm trong không gian địa chỉ ảo (Virtual Memory). Tiến trình người dùng không thể trực tiếp truy cập vào không gian kernel. Thay vào đó, nó chỉ có quyền truy cập vào không gian người dùng (User-space) và cần sao chép dữ liệu vào không gian kernel thông qua cơ chế do hệ điều hành cung cấp (như các lời gọi hệ thống - System call). Sau đó, kernel sẽ xử lý dữ liệu theo yêu cầu của tiến trình.
IO là gì
Trong hệ thống máy tính, I/O (Input/Output) có nghĩa là đầu vào và đầu ra. Tùy theo đối tượng hoạt động, I/O có thể được phân loại thành nhiều mô hình khác nhau như: I/O đĩa, I/O mạng, I/O ánh xạ bộ nhớ, I/O trực tiếp, I/O cơ sở dữ liệu, v.v. Bất kỳ hệ thống nào có các kiểu đầu vào và đầu ra đều có thể được coi là một hệ thống I/O. Có thể nói, I/O chính là kênh trao đổi dữ liệu và cầu nối tương tác giữa con người 🙍♂️ và máy tính 💻 trong toàn bộ hệ điều hành. Đây là một khái niệm phổ quát, không phụ thuộc vào ngôn ngữ lập trình hay công nghệ phát triển cụ thể.
Trong các hệ thống ngày nay, I/O đóng vai trò quan trọng hàng đầu. Các hệ thống hiện đại thường phải xử lý khối lượng lớn tệp tin và các hoạt động cơ sở dữ liệu phức tạp. Những hoạt động này phụ thuộc nhiều vào hiệu suất I/O của hệ thống, và đây thường là nguyên nhân chính gây ra tắc nghẽn hiệu năng. Nếu hiệu suất I/O không đủ cao, toàn bộ hệ thống sẽ bị chậm lại, bất kể CPU hay bộ nhớ có mạnh đến đâu.
Để cải thiện hiệu suất I/O, các giải pháp tối ưu hóa đã được áp dụng, chẳng hạn như:
- Bổ sung bộ nhớ đệm trong kiến trúc hệ thống nhằm giảm độ trễ và tăng tốc độ phản hồi.
- Thay thế ổ cứng cơ học (HDD) truyền thống bằng ổ đĩa thể rắn (SSD) để tăng tốc độ truy cập dữ liệu ở cấp độ phần cứng.
Có thể nói, phần lớn không gian tối ưu hóa hệ thống nằm ở việc cải thiện liên kết I/O, bởi vì đây thường là điểm nghẽn chính. Trong khi đó, hiệu suất của CPU và bộ nhớ hiếm khi là nguyên nhân gây ra tắc nghẽn trong hệ thống hiện đại.
Vậy dữ liệu vào ở đâu và ra ở đâu?
- Input: Dữ liệu được nhập vào bộ nhớ (RAM).
- Output: Dữ liệu được xuất ra các thiết bị I/O (như ổ đĩa, mạng, hoặc các thiết bị cần tương tác với bộ nhớ).
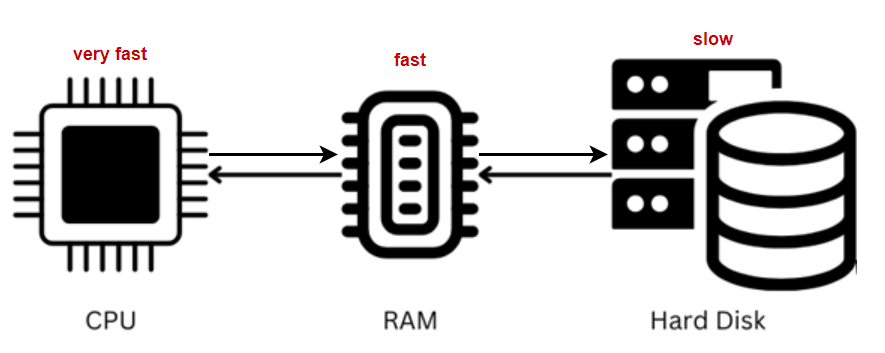 Flow IO
Flow IO
Một vùng của bộ nhớ chính (thường là DRAM) được dùng để lưu trữ tạm thời nội dung của hệ thống tệp (file system), bao gồm cả dữ liệu và siêu dữ liệu.
Giao tiếp IO (Input/Output)
Giao tiếp IO là quá trình truyền dữ liệu trực tiếp giữa các thiết bị ngoại vi (thiết bị IO) và bộ nhớ thông qua các giao diện IO. Hệ điều hành cung cấp các giao diện IO (được đóng gói sẵn) mà chúng ta có thể sử dụng trực tiếp trong quá trình lập trình.
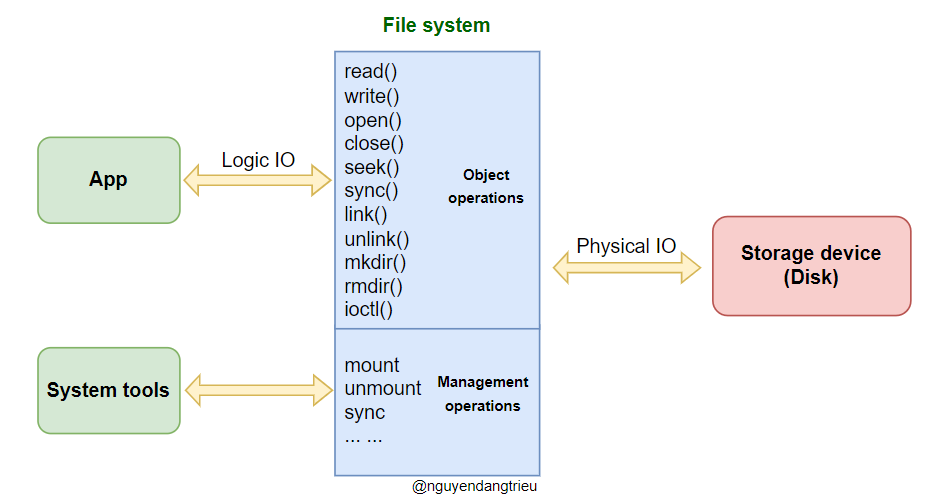
Đối với người dùng, khi muốn giao tiếp với các thiết bị ngoại vi, chỉ cần sử dụng các lệnh gọi hệ thống (System Call) được hệ điều hành hỗ trợ, mà không cần phải quan tâm đến cách thức hoạt động bên trong.
Bộ nhớ đệm ở khắp mọi nơi
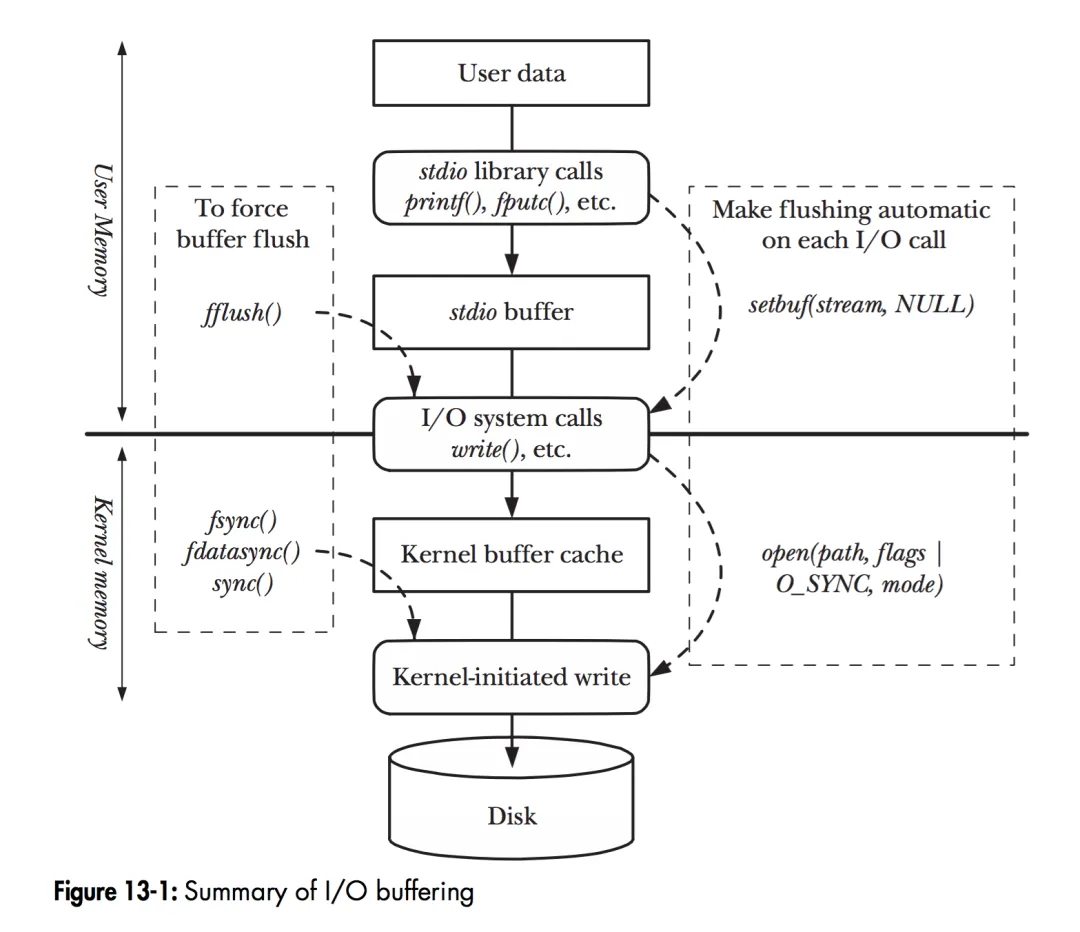
Khi chương trình thực hiện các thao tác trên tệp, dữ liệu người dùng (User Data) được chuyển đến đĩa (Disk) theo các cấp bậc từ trên xuống dưới, như trong hình minh họa. Hệ thống được chia thành chế độ người dùng (User Mode) và chế độ nhân (Kernel Mode), được phân cách bởi đường liền màu đen ở giữa.
1.Thao tác tệp ở User Mode
- Thư viện stdio (C Library): Các hàm thao tác tệp như
fread,fwriteđược cung cấp bởi thư viện C (stdio). Những hàm này được đóng gói để hỗ trợ đa nền tảng và hoạt động trong User Mode. - Bộ đệm stdio (Stdio Buffer):
- Các hàm
stdiosử dụng bộ đệm riêng (stdio buffer) trong chế độ người dùng để giảm tần suất gọi lệnh gọi hệ thống (System Call), vốn rất tốn kém. Ví dụ: Khi bạn ghi hoặc đọc tệp với kích thước nhỏ, thư viện stdio sẽ gom dữ liệu vào bộ đệm trước, sau đó mới gọi một lần ghi/đọc lớn hơn để cải thiện hiệu suất. - Người dùng có thể tùy chỉnh bộ đệm này bằng các hàm như
setbuf()hoặc xóa bộ đệm bằng cách gọifflush().
- Các hàm
2.Thao tác tệp ở Kernel Mode
- Kernel Buffer Cache: Khi Kernel Mode, giữa các lệnh gọi hệ thống (read, write) và thao tác thực tế trên đĩa, có một lớp bộ đệm gọi là Kernel Buffer Cache.
- Trong Linux, lớp này gồm hai khái niệm:
- Page Cache: Lưu trữ nội dung của các tệp, liên quan chặt chẽ đến hệ thống tệp (file system).
- Buffer Cache: Lưu trữ dữ liệu của các khối thiết bị lưu trữ (như sector của đĩa), không phụ thuộc vào hệ thống tệp. Hai khái niệm này đôi khi dễ bị nhầm lẫn, nhưng Page Cache thường được dùng cho tệp, còn Buffer Cache dùng cho dữ liệu thiết bị lưu trữ cấp thấp.
Ngăn xếp IO của Linux
Mặc dù chúng ta có thể đơn giản đọc/ghi dữ liệu từ các thiết bị ngoại vi thông qua các lệnh gọi hệ thống (System Call), nhưng lợi ích thực sự đến từ kiến trúc ngăn xếp IO hoàn chỉnh của Linux.
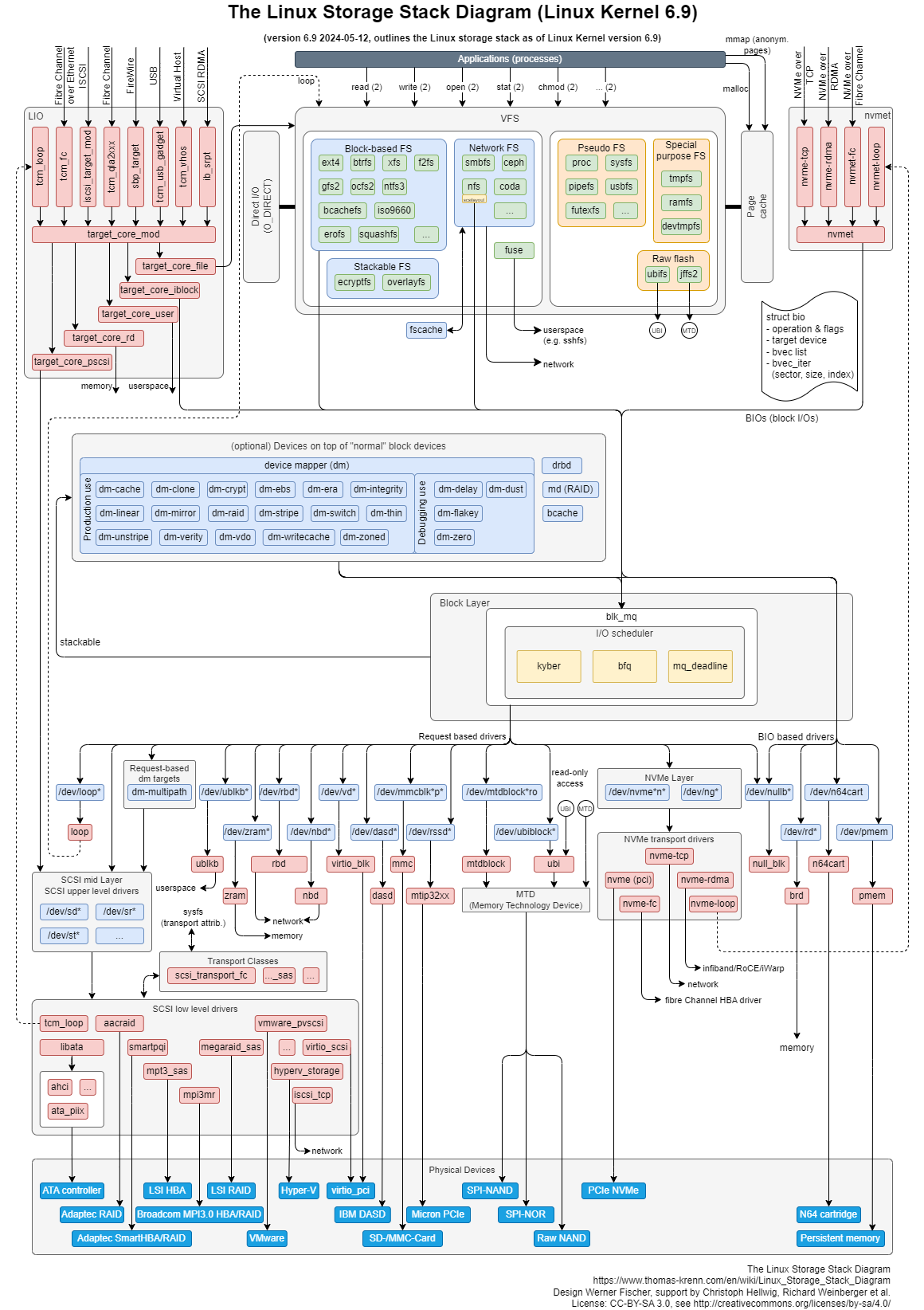
Trong Linux, ngăn xếp IO được chia thành ba cấp độ chính:
Lớp hệ thống tệp (File System Layer)
- Tại lớp này, các lệnh gọi hệ thống như write(2) sẽ sao chép dữ liệu từ không gian người dùng (User Space) sang Bộ nhớ đệm của hệ thống tệp (File System Buffer) trong không gian kernel.
- Bộ đệm này giúp tăng hiệu suất bằng cách gom các thao tác nhỏ lẻ thành một khối lớn hơn trước khi đồng bộ với lớp bên dưới.
Lớp khối (Block Layer)
- Lớp khối (Block Layer) quản lý hàng đợi I/O (IO Queue) của các thiết bị lưu trữ khối (Block Storage Devices). Nhiệm vụ chính của lớp này là hợp nhất và sắp xếp các yêu cầu I/O theo thứ tự tối ưu, nhằm cải thiện hiệu suất truy cập các thiết bị lưu trữ
Lớp thiết bị (Device Layer)
- Đây là lớp trực tiếp tương tác với phần cứng, sử dụng DMA (Direct Memory Access) để truyền dữ liệu giữa bộ nhớ và thiết bị lưu trữ cụ thể mà không cần CPU can thiệp nhiều.
Các cơ chế được kết nối với ngăn xếp IO của Linux như thế nào?
Hình trên hơi phức tạp. Hãy vẽ một sơ đồ đơn giản và thêm vị trí của các cơ chế này
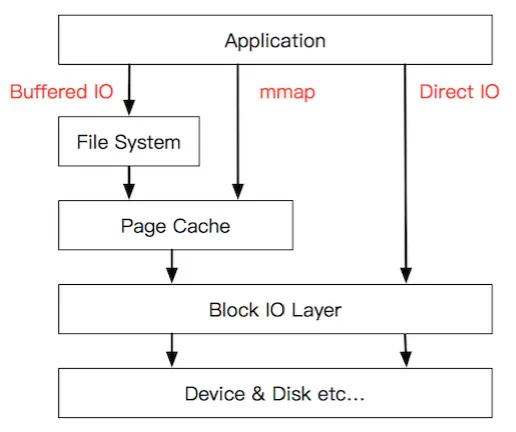
Quá trình đọc dữ liệu trong Buffered I/O truyền thống với hàm `read(2)?
Ngăn xếp IO trong Linux liên kết chặt chẽ với các cơ chế hoạt động từ việc mở tệp (open) đến đọc tệp (read). Dưới đây là quy trình đơn giản hóa của Buffered IO trong trường hợp đọc một tệp không tồn tại trong Cache:
Mở tệp open(2)
Khi thực hiện lệnh open(2) để mở tệp, kernel sẽ thiết lập các cấu trúc dữ liệu liên quan, như mô tả thông tin về tệp trong hệ thống.
Đọc tệp read(2)
Lệnh read(2) được gọi để yêu cầu đọc dữ liệu từ tệp. Quá trình này diễn ra qua các bước sau:
- Lớp hệ thống tệp (File System layer): Kernel kiểm tra Page Cache của hệ thống tệp. Nếu dữ liệu cần đọc không tồn tại trong Page Cache, kernel sẽ ánh xạ vị trí trên đĩa cần đọc.
- Lớp khối (Block Layer):
- Yêu cầu đọc dữ liệu được gửi đến hàng đợi IO của thiết bị khối (IO Queue).
- Tại đây, hệ thống quản lý và sắp xếp các yêu cầu IO để tối ưu hóa hiệu suất truy cập đĩa.
- Lớp trình điều khiển thiết bị (Device Driver layer):
- Sau khi yêu cầu được xử lý tại hàng đợi, kernel chuyển nó đến trình điều khiển thiết bị (Device Driver).
- Trình điều khiển sử dụng DMA để đọc các cung đĩa tương ứng vào Bộ nhớ đệm của kernel (Kernel Buffer).
Trả dữ liệu về không gian người dùng
Khi dữ liệu đã được đọc từ đĩa vào bộ đệm kernel: Kernel sẽ sao chép dữ liệu từ Bộ nhớ đệm kernel (Kernel Buffer) sang Bộ đệm của người dùng (User Buffer) được chỉ định trong lệnh read(2).
Blocking/Non-blocking và Synchronous/Asynchronous
“If routine A calls routine B then routine A is the caller and routine B is the callee. i.e. the caller is the routine which is calling the callee.”
Blocking/non-blocking
Đối tượng hướng đến ở đây là caller.
- Blocking: Điều đó có nghĩa là sau khi gọi một hàm, caller sẽ đợi giá trị trả về của hàm và luồng (thread) ở trạng thái treo.
- Non-blocking: Điều đó có nghĩa là sau khi gọi một hàm, caller không đợi giá trị trả về của hàm và luồng (thread) tiếp tục chạy các chương trình khác (thực hiện các thao tác khác hoặc tiếp tục duyệt xem hàm có trả về giá trị hay không).
Synchronous/Asynchronous
Đối tượng hướng đến là callee.
Synchronous execution means the first task in a program must finish processing before moving on to executing the next task whereas asynchronous execution means a second task can begin executing in parallel, without waiting for an earlier task to finish.
Mô hình I/O
Phần sau đây lấy hàm recvfrom/recv làm ví dụ. Cả hai hàm này là lệnh gọi hệ thống (system calls) của kernel, được sử dụng để nhận dữ liệu từ socket (đã được kết nối) và lấy địa chỉ của nguồn gửi dữ liệu.
1
ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags)
Với:
sockfd: Mô tả file của socket dùng để nhận dữ liệu.buff: Bộ đệm lưu trữ dữ liệu nhận được từ hàm recv.nbytes: Độ dài tối đa của bộ đệm buff.flags: Thường đặt là 0.
Trong hệ thống Linux, socket được trừu tượng hóa như một luồng. Việc thực hiện IO là thao tác đọc/ghi luồng này.
Khi thực hiện một thao tác recv, dữ liệu sẽ đi qua hai giai đoạn chính:
- Stage 1: Chờ dữ liệu sẵn sàng -> Hệ điều hành chờ gói dữ liệu từ mạng, sau đó lưu vào bộ đệm trong kernel.
- Stage 2: Sao chép dữ liệu -> Dữ liệu từ bộ đệm kernel được sao chép sang vùng nhớ của ứng dụng.
Hoạt động của socket stream:
- Stage 1: Chờ gói dữ liệu đến từ mạng và được lưu trữ trong một bộ đệm của kernel.
- Stage 2: Sao chép dữ liệu từ bộ đệm kernel sang bộ đệm của ứng dụng (buff).
Blocking IO
Điều đó có nghĩa là sau khi gọi một hàm I/O, caller sẽ chờ đợi kết quả trả về và luồng (thread) sẽ bị chặn cho đến khi tác vụ hoàn thành.
🔹 Ví dụ thực tế: Nếu bạn đến phòng thử đồ trong trung tâm mua sắm và có người đang sử dụng, bạn phải đứng chờ ở ngoài cho đến khi người bên trong ra ngoài, không thể làm việc khác trong lúc chờ.
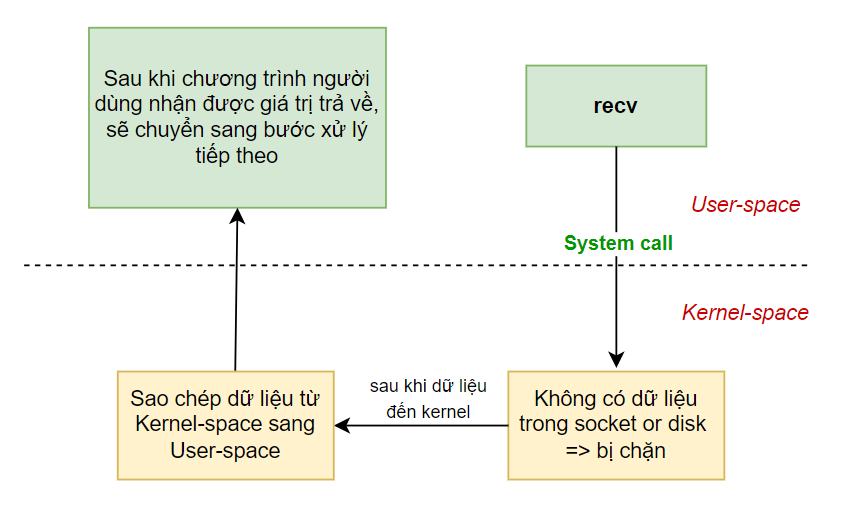
Quá trình thực hiện lệnh gọi hệ thống recv()
Stage 1: Chuẩn bị dữ liệu
Khi tiến trình người dùng gọi lệnh hệ thống recv(), kernel bắt đầu giai đoạn đầu tiên của IO – chuẩn bị dữ liệu.
- Trong mạng IO, dữ liệu có thể chưa sẵn sàng ngay tại thời điểm gọi lệnh. Ví dụ: kernel phải chờ một gói UDP hoàn chỉnh được nhận trước khi xử lý.
- Kernel sẽ đợi dữ liệu đến và sao chép dữ liệu vào bộ đệm của mình. Trong thời gian này, tiến trình người dùng bị chặn (nếu tiến trình lựa chọn chế độ chặn).
Stage 2: Sao chép dữ liệu
Sau khi dữ liệu sẵn sàng:Kernel sao chép dữ liệu từ bộ đệm của kernel sang vùng nhớ của tiến trình người dùng. Sau đó, kernel trả về kết quả. Tiến trình người dùng sẽ được bỏ trạng thái chặn và tiếp tục thực thi.
Đặc điểm của Block IO là tiến trình sẽ chặn ở cả hai giai đoạn (chờ dữ liệu và sao chép dữ liệu).
👍 Ưu điểm
- Khả năng trả lại dữ liệu kịp thời: Dữ liệu được xử lý ngay khi sẵn sàng, tránh tình trạng chậm trễ.
- Giảm độ phức tạp cho các nhà phát triển kernel: Kernel không cần xử lý logic phức tạp liên quan đến chế độ không chặn.
👎 Nhược điểm:
- Giảm hiệu suất: Từ góc độ tiến trình người dùng, việc bị chặn sẽ làm giảm hiệu quả, đặc biệt khi dữ liệu cần thời gian dài để sẵn sàng.
Non-Blocking IO
Điều đó có nghĩa là sau khi gọi một hàm I/O, caller không cần chờ đợi kết quả và luồng (thread) tiếp tục thực thi các công việc khác. Caller có thể kiểm tra trạng thái của tác vụ I/O theo cơ chế Polling (kiểm tra liên tục) hoặc xử lý song song các nhiệm vụ khác trong khi chờ kết quả.
🔹 Ví dụ thực tế: Khi ta đặt thức ăn bên ngoài, thay vì đứng đợi ở cửa thì trong khoảng thời gian đó ta có thể làm được rất nhiều việc khác ví dụ như xem TV, dọn nhà, … và thỉnh thoảng ra kiểm tra xem thức ăn đã giao tới chưa.
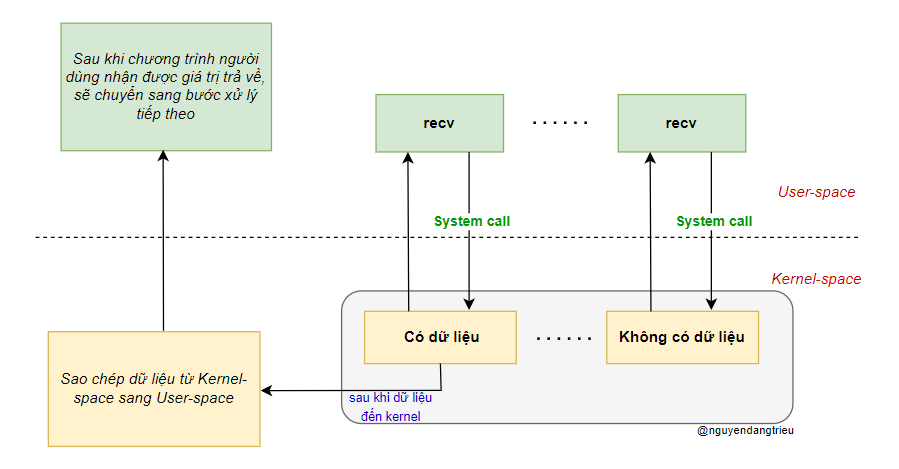
Khi tiến trình người dùng thực hiện thao tác đọc, nếu dữ liệu trong kernel chưa sẵn sàng, hệ thống sẽ không chặn tiến trình mà trả về lỗi ngay lập tức. Tiến trình người dùng sẽ biết dữ liệu chưa sẵn sàng và có thể lặp lại thao tác đọc sau. Khi dữ liệu đã sẵn sàng, kernel sẽ ngay lập tức sao chép dữ liệu vào bộ nhớ người dùng và trả về kết quả.
Đặc điểm của non-blocking IO là tiến trình người dùng cần chủ động kiểm tra liên tục xem dữ liệu đã sẵn sàng hay chưa.
IO multiplexing
Một hoặc nhiều luồng (thread) dùng để xử lý nhiều kết nối đồng thời.
Ví dụ: Trong 1 lớp học, các học sinh đang làm bài thì cô giáo nói sẽ kiểm tra bài tập để chấm điểm khi một bạn nào đó làm xong thì giơ tay lên. Ta có thể hiểu ở đây: cô giáo - ứng dụng người dùng, học sinh - recv(), bài tập - dữ liệu mà ứng dụng người dùng cần.
“Đối với một cổng I/O, nếu ta chỉ có một kết nối, thì gọi select() trước rồi recv() sau không có lợi hơn so với chỉ dùng recv() (vì vẫn bị chặn 2 lần - 1 là khi gọi select() - 2 là khi gọi recv()). Tuy nhiên nếu ta có nhiều kết nối, select() giúp theo dõi tất cả cùng lúc, giúp tiết kiệm tài nguyên CPU hơn.”
Điểm quan trọng là có thể giám sát nhiều cổng I/O cùng lúc và kiểm tra trạng thái của nhiều thao tác đọc/ghi, chỉ thực sự gọi hàm I/O khi có dữ liệu sẵn sàng để đọc hoặc ghi.
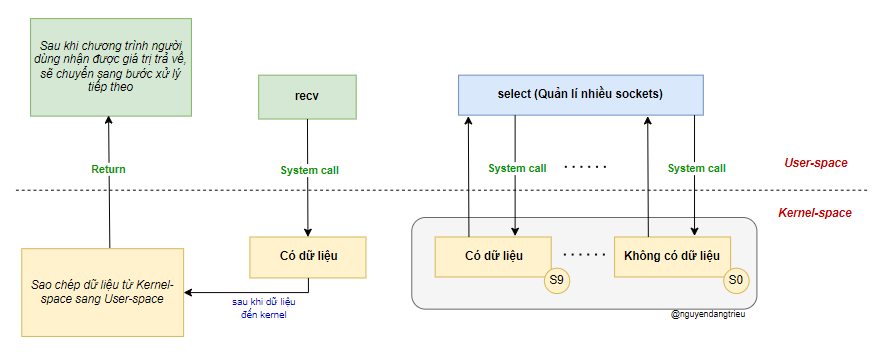
Mô hình này thực ra giống hệt Blocking I/O, cả hai đều là mô hình chặn, nhưng có một lớp proxy lựa chọn (select) được thêm vào socket. Select giúp nâng cao hiệu suất bằng cách theo dõi nhiều socket và kiểm tra xem có dữ liệu đến hay không.
Khi phát hiện một hoặc nhiều bộ mô tả tệp (file descriptor) có dữ liệu đến, hàm select() sẽ trả về. Lúc này, ta gọi hàm recv() (hàm này cũng vẫn là thao tác chặn), dữ liệu được sao chép từ không gian kernel sang không gian người dùng, rồi recv() mới trả về kết quả.
Multiplexing I/O cho phép một tiến trình có thể chờ trên nhiều bộ mô tả tệp I/O đồng thời. Kernel sẽ giám sát các bộ mô tả này (tức là các socket). Khi bất kỳ socket nào sẵn sàng để đọc, các hàm
select(),poll(), hoặcepoll()sẽ trả về để tiến trình tiếp tục xử lý.
Có ba phương pháp phổ biến để giám sát nhiều socket:
select()poll()epoll()
Ba phương pháp này khác nhau về hiệu suất, trong đó epoll() thường được ưu tiên trong các hệ thống có nhiều kết nối vì khả năng mở rộng tốt hơn so với select() và poll().
Signal-Driven I/O (SIGIO)
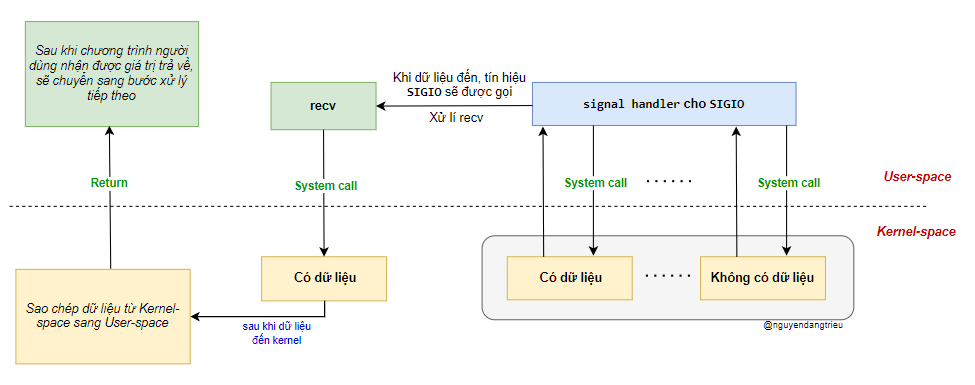
Trong lập trình Linux, I/O điều khiển bằng tín hiệu (Signal-Driven I/O) là một cơ chế giúp chương trình không bị chặn khi chờ dữ liệu đến. Thay vì phải liên tục kiểm tra (polling) hay bị chặn tại một lệnh gọi hệ thống như recv(), chương trình có thể đăng ký một trình xử lý tín hiệu (signal handler) để xử lý dữ liệu một cách bất đồng bộ.
Cách hoạt động của Signal-Driven I/O
Đăng ký tín hiệu xử lý I/O:
- Chương trình thiết lập một hàm xử lý tín hiệu (signal handler) thông qua
sigaction()hoặcsignal(). - Khi dữ liệu đến, hệ điều hành sẽ gửi tín hiệu
SIGIOđể thông báo cho chương trình.
khi đăng ký tín hiệu, chương trình không cần phải chờ dữ liệu mà có thể tiếp tục thực hiện các tác vụ khác. Nhận dữ liệu khi có tín hiệu:
Khi dữ liệu đến, hệ điều hành ngắt chương trình, chuyển đến hàm xử lý tín hiệu đã đăng ký. Trong hàm này, chương trình gọi recv() để đọc dữ liệu từ kernel space vào user space. Do đã có dữ liệu sẵn, recv() sẽ không bị chặn. Sau khi xử lý xong dữ liệu, chương trình quay lại tiếp tục công việc trước đó.
🔹 Sự khác biệt giữa Signal-Driven I/O và Non-Blocking I/O (O_NONBLOCK)
🚫 Không nên nhầm lẫn O_NONBLOCK với Signal-Driven I/O!
O_NONBLOCK→ Tiến trình phải tự kiểm tra liên tục (polling) xem có dữ liệu hay chưa.- Signal-Driven I/O (SIGIO) → Kernel tự động thông báo khi có dữ liệu, tiến trình không cần kiểm tra liên tục.
Asynchronous IO
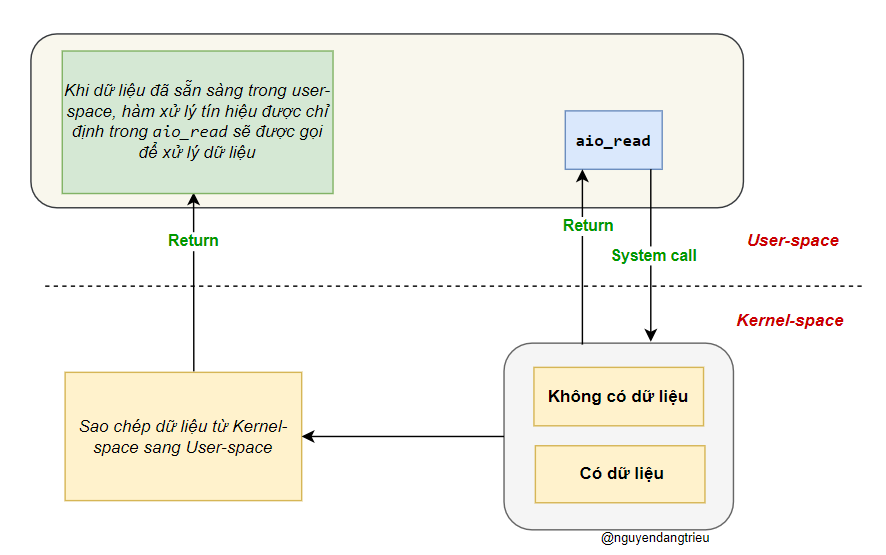
Asynchronous IO giúp tăng hiệu suất vì chương trình không cần phải đợi dữ liệu. Cách hoạt động của nó như sau:
Gửi yêu cầu đọc
- Hàm aio_read được gọi để yêu cầu đọc dữ liệu từ kernel.
- Chương trình chỉ cần cung cấp bộ đệm để lưu dữ liệu khi có sẵn.
- aio_read trả về ngay lập tức, không chờ dữ liệu, giúp chương trình có thể làm việc khác.
Hệ điều hành xử lý dữ liệu
- Khi dữ liệu đến, kernel tự động sao chép nó vào bộ đệm của chương trình.
- Khi hoàn thành, kernel gửi tín hiệu thông báo cho chương trình biết rằng dữ liệu đã sẵn sàng.
Ứng dụng xử lý dữ liệu
- Sau khi nhận tín hiệu, chương trình có thể tiếp tục xử lý mà không cần gọi thêm
recv.
Khác biệt giữa Asynchronous IO và Signal-Driven I/O
| Tiêu chí | Asynchronous IO | Signal-Driven I/O |
|---|---|---|
| Khi dữ liệu đến | Kernel tự động sao chép vào bộ đệm của chương trình | Dữ liệu vẫn ở kernel, chờ chương trình gọi recv() để lấy |
| Cách dữ liệu di chuyển | Kernel chủ động đẩy dữ liệu vào không gian người dùng | Chương trình phải gọi recv() để lấy dữ liệu |
| Hiệu suất | Cao - vì không cần gọi recv() | Thấp - do phải gọi recv(), tốn tài nguyên |
Reference
- https://everything2.com/title/caller+vs+callee
- https://www.koyeb.com/blog/introduction-to-synchronous-and-asynchronous-processing#executing-tasks-sync-versus-async
- https://rickhw.github.io/2019/02/27/ComputerScience/IO-Models/