Quá trình Compile
🍀 Lời mở đầu
𝕀. Giới thiệu
 Quá trình compile
Quá trình compile
Nếu bạn đã từng lập trình bằng C, C++ hoặc Java, chắc hẳn bạn đã từng xây dựng (Build) hoặc biên dịch (Compile) mã nguồn mà mình viết để chạy chương trình, hoặc cũng có thể từng gặp phải lỗi biên dịch do viết sai mã nguồn.
Nếu bạn chưa hiểu rõ quá trình biên dịch thực sự làm những gì và chỉ mơ hồ nghĩ rằng “Biên dịch là kiểm tra cú pháp mã nguồn và thực thi chương trình”, thì đây là lúc để tìm hiểu chi tiết hơn.
※ Hình minh họa hoặc ví dụ sẽ tập trung vào quá trình biên dịch mã C trên môi trường Linux, vì vậy có thể có sự khác biệt tùy thuộc vào ngôn ngữ hoặc môi trường bạn sử dụng.
𝕀𝕀. Định nghĩa Compile
Biên dịch là quá trình chuyển đổi mã nguồn viết bằng ngôn ngữ mà con người có thể hiểu (ngôn ngữ cấp cao như C, C++, Java, v.v.) thành ngôn ngữ mà CPU có thể hiểu được (ngôn ngữ cấp thấp, tức là mã máy).
Mã nguồn mà chúng ta viết bằng C, C++, Java, v.v. không thể được máy tính hiểu trực tiếp, vì máy tính chỉ hiểu mã máy, được biểu diễn bằng các số 0 và 1. Vì vậy, một quá trình biên dịch là cần thiết để chuyển đổi mã nguồn của chúng ta thành mã máy mà máy tính có thể hiểu và thực thi.
Mã nguồn sau khi được biên dịch sẽ trở thành một tệp thực thi chứa mã máy. Khi chạy tệp này, nội dung của nó sẽ được nạp vào bộ nhớ thông qua Loader của hệ điều hành và chương trình sẽ được thực thi.
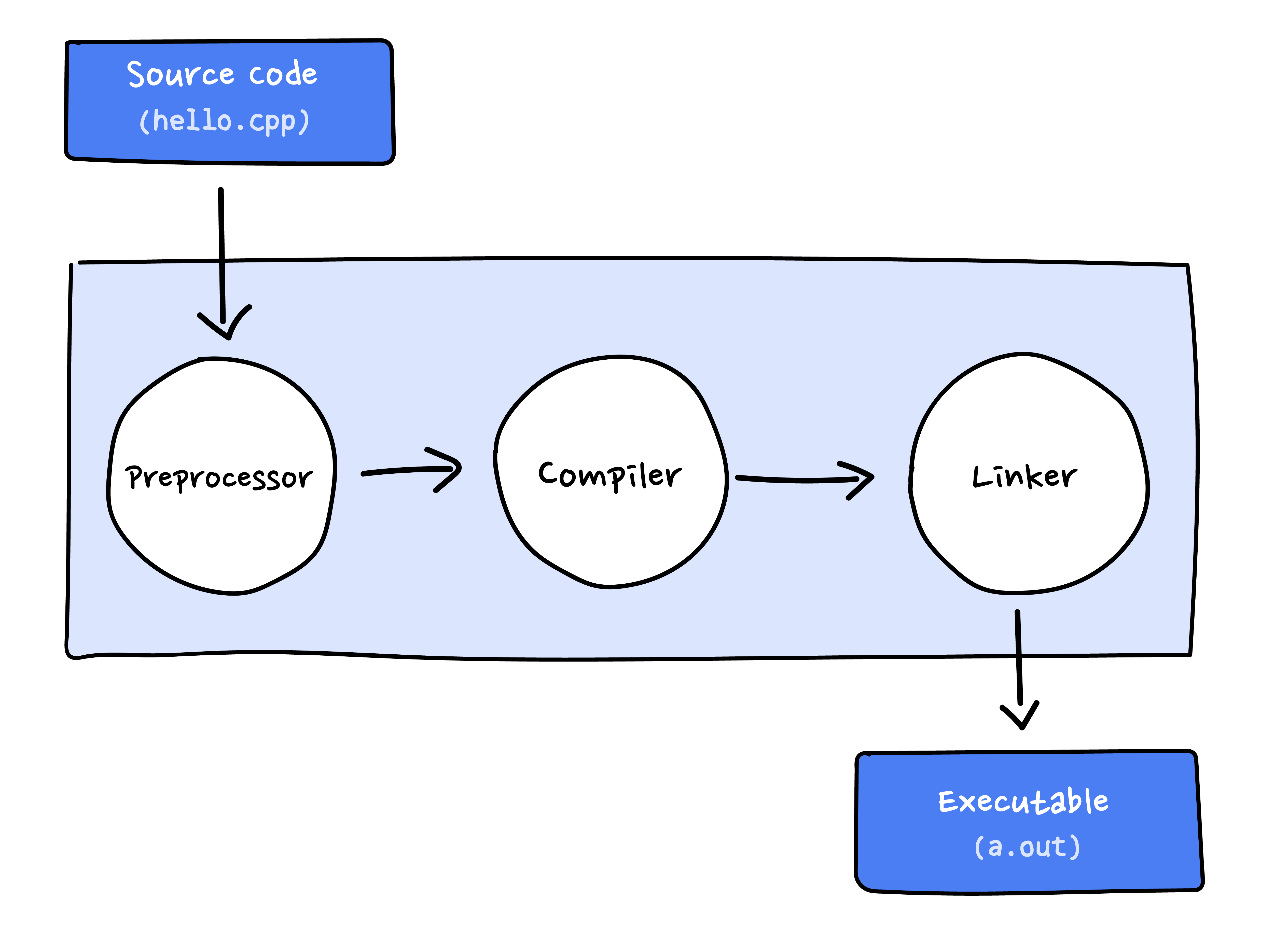
𝕀𝕀𝕀. Quá trình Compile

Quá trình biên dịch được chia thành 4 bước:
- Quá trình tiền xử lý (Pre-processing).
- Quá trình biên dịch (Compilation).
- Quá trình lắp ráp (Assembly).
- Quá trình liên kết (Linking).
Cả 4 bước này thường được gọi chung là quá trình biên dịch hoặc quá trình xây dựng (build). Đôi khi, quá trình biên dịch và quá trình liên kết được tách riêng ra và gọi tên khác nhau.
Thông thường, quá trình xây dựng (build) được hiểu theo nghĩa rộng hơn, bao gồm cả biên dịch và liên kết (Build = Compile + Link). Tuy nhiên, trong một số tình huống, “Quá trình biên dịch” có thể chỉ đề cập đến bước biên dịch mà không bao gồm liên kết, vì vậy bạn cần hiểu nó theo ngữ cảnh cụ thể.
Hãy cùng tìm hiểu chi tiết từng bước trong quá trình này.
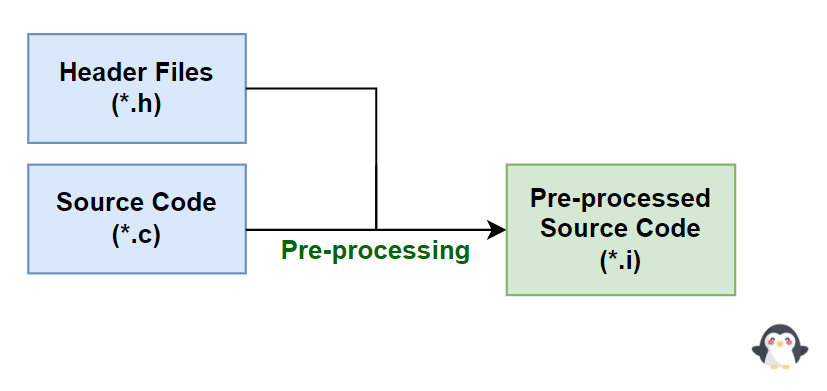
1. Quá trình tiền xử lý (Pre-processing)
 Tiền xử lí
Tiền xử lí
Pre-processing là quá trình chuyển đổi Source Code (*.c) thành Source Code đã được xử lý (*.i) thông qua Pre-processor. Trong quá trình này, có ba công việc chính thường được thực hiện:
- Loại bỏ Comments: Tất cả các chú thích trong mã nguồn sẽ bị loại bỏ. Chú thích chỉ là phần thông tin dành cho con người, không cần thiết cho máy tính hiểu.
- Chèn
(*.h): Khi gặp chỉ thị#include, Pre-processor sẽ tìm file(*.h)tương ứng và sao chép tất cả nội dung trong file đó vào mã nguồn(*.c). File(*.h)không được biên dịch trực tiếp mà chỉ là nơi chứa các khai báo, chẳng hạn như khai báo hàm, cấu trúc dữ liệu, hằng số, … .Những khai báo trong file(*.h)sẽ được sử dụng để kết hợp với tệp đối tượng(*.o), chứa phần định nghĩa thực sự của hàm trong quá trình liên kết (Linking). - Sử dụng Macro: Các Macro được định nghĩa bằng chỉ thị
#definesẽ được tiền xử lý và lưu trữ. Khi gặp các chuỗi giống nhau trong mã nguồn, Pre-processor sẽ thay thế chúng bằng nội dung mà macro đã được định nghĩa. Nói một cách đơn giản, Preprocessor sẽ tìm kiếm tên của macro và thay thế nó bằng giá trị hoặc mã mà macro đã khai báo. Ví dụ:#define PI 3.14
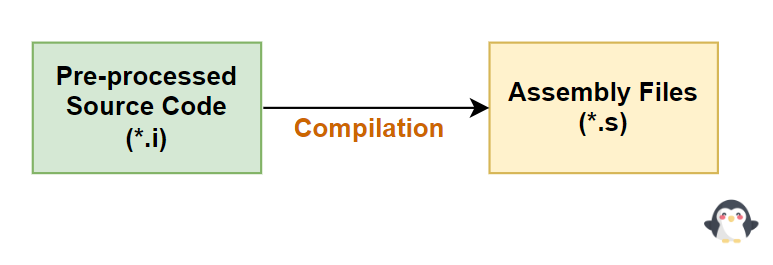
2. Quá trình biên dịch (Compilation)
 Biên dịch
Biên dịch
- Compilation là quá trình thông qua trình biên dịch (Compiler) để chuyển đổi Source Code đã qua tiền xử lý
(*.i)thành tệp mã Assembly(*.s). - Trong quá trình này, những gì chúng ta thường nghĩ khi nói đến việc biên dịch, đó là kiểm tra cú pháp của ngôn ngữ. Bên cạnh đó, quá trình này còn thực hiện việc cấp phát bộ nhớ cho các khu vực tĩnh (Data, BSS). Những khu vực này chứa dữ liệu và các biến không được khởi tạo, và việc cấp phát bộ nhớ là bước cần thiết để chuẩn bị cho các quá trình tiếp theo.
Cấu trúc Compiler
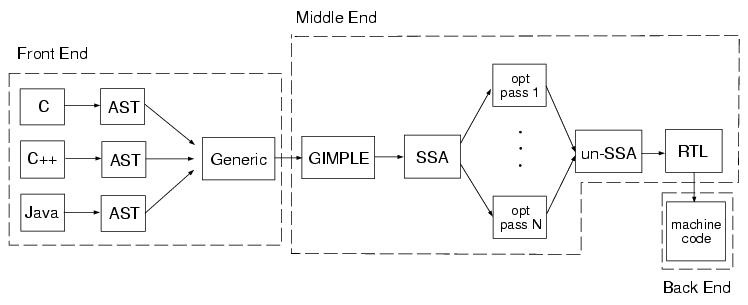
Compiler bao gồm ba giai đoạn:
- Front-end.
- Middle-end.
- Back-end.
 Cấu trúc Compiler
Cấu trúc Compiler
Front-End
Trong giai đoạn này, các phần liên quan đến từng ngôn ngữ lập trình sẽ được xử lý riêng biệt.
- Kiểm tra mã nguồn: Mã nguồn sẽ được kiểm tra kỹ lưỡng để đảm bảo tuân thủ đúng cú pháp và ngữ nghĩa của ngôn ngữ lập trình. Quá trình này bao gồm phân tích từ vựng (lexical analysis), cú pháp (syntax analysis), và ngữ nghĩa (semantic analysis).
- Tạo cây GIMPLE: Sau khi mã nguồn vượt qua bước kiểm tra, một cây GIMPLE sẽ được tạo ra. Đây là một cấu trúc dữ liệu biểu diễn chương trình dưới dạng cây, giúp thể hiện logic của mã nguồn một cách rõ ràng và dễ dàng xử lý hơn.
Tóm lại, mỗi ngôn ngữ lập trình, chẳng hạn như C, C++ hay Java, v.v. sẽ được xử lý theo các quy tắc riêng của nó trước khi được chuyển đổi sang GIMPLE – một dạng biểu diễn trung gian (Intermediate Representation – IR) chung. GIMPLE đóng vai trò là cầu nối, giúp hệ thống xử lý những phần phụ thuộc vào ngôn ngữ một cách nhất quán và hiệu quả.
Middle-End
Trong quá trình Middle-end, các tối ưu hóa không phụ thuộc vào kiến trúc được thực hiện.
- Tối ưu hóa không phụ thuộc vào kiến trúc có nghĩa là những tối ưu hóa này có thể được áp dụng bất kể kiến trúc CPU là gì (như ARM, x86, v.v.). Các tối ưu hóa này thường liên quan đến việc cải thiện hiệu suất chương trình mà không cần quan tâm đến phần cứng cụ thể.
Sau khi nhận được cây GIMPLE từ Front-end, Middle-end thực hiện các tối ưu hóa không phụ thuộc vào kiến trúc. Sau đó, quá trình này tạo ra RTL (Register Transfer Language), là một dạng biểu diễn trung gian giữa ngôn ngữ cấp cao và mã Assembly. RTL giúp trình biên dịch chuyển đổi mã nguồn thành dạng có thể dễ dàng chuyển thành mã máy cho kiến trúc cụ thể trong giai đoạn Back-end.
Back-End
Trong quá trình Back-end, các tối ưu hóa phụ thuộc vào kiến trúc được thực hiện.
- Tối ưu hóa phụ thuộc vào kiến trúc có nghĩa là các tối ưu hóa này được thực hiện dựa trên đặc điểm và khả năng của từng kiến trúc CPU cụ thể. Ví dụ, cùng một chức năng nhưng sẽ được thay thế bằng những lệnh hiệu quả hơn tùy thuộc vào kiến trúc của CPU (ARM, x86, v.v.) để nâng cao hiệu suất.
Sau khi nhận được RTL từ Middle-end, Back-end thực hiện tối ưu hóa dựa trên kiến trúc và khi quá trình này hoàn tất, mã Assembly sẽ được tạo ra.
Việc thực hiện tối ưu hóa phụ thuộc vào kiến trúc sẽ tạo ra mã Assembly mà chỉ có thể được hiểu bởi kiến trúc đó. Điều này có nghĩa là mã Assembly sẽ không thể được sử dụng nếu không tương thích với kiến trúc CPU cụ thể.
3. Quá trình lắp ráp (Assembly)
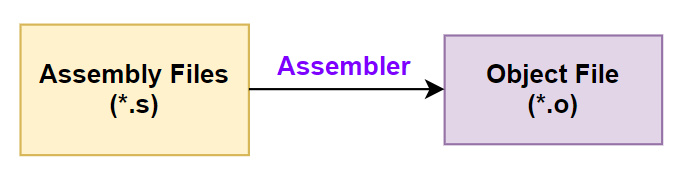 Assembler
Assembler
Quá trình Assembly chuyển đổi File Assembly (.s) thành Object File (.o), Object File này sẽ chứa các mã máy (Machine code) tương ứng với các lệnh đã được viết trong mã Assembly. Tuy nhiên, Object File vẫn cần phải trải qua quá trình liên kết (Linking) để kết hợp với các Object File khác và thư viện để tạo thành một tệp thực thi hoàn chỉnh.
a. Object file
Tệp đối tượng (Object file) là file chứa mã máy đã được biên dịch từ Source Code, nhưng chưa phải là tệp thực thi hoàn chỉnh. File này thường có phần mở rộng (*.o) trong môi trường Linux.
- ELF (Executable and Linking Format): Định dạng tệp đối tượng sử dụng trên hệ điều hành Linux.
b. Object File Format
 Object File Format
Object File Format
- Object File Header: Phần header chứa thông tin cơ bản về file đối tượng.
- Text Section: Phần chứa code đã được chuyển đổi thành mã máy (Machine code 01011…).
- Data Section: Phần chứa dữ liệu như các biến toàn cục (Global) và biến tĩnh (static).
- Symbol Table Section: Phần định nghĩa tên và địa chỉ của các biểu tượng (symbol) được tham chiếu trong mã nguồn.
- Relocation Information Section: Phần ghi lại những thông tin cần thay đổi vị trí của các biểu tượng (symbol) sau khi vị trí của chúng được xác định trong quá trình liên kết (Linking).
- Debugging Information Section: Phần chứa thông tin cần thiết cho việc gỡ lỗi (Debugging).
Phần quan trọng ở đây là phần bảng ký hiệu (Symbol Table) và phần thông tin tái phân bố (Relocation Information).
Ký hiệu (Symbol) là tên được sử dụng để xác định các hàm hoặc biến, và trong Bảng ký hiệu (Symbol Table), nó chứa thông tin về các ký hiệu được tham chiếu trong Object File (như tên và địa chỉ dữ liệu).
Lúc này, Symbol Table của Object File chỉ chứa thông tin về các symbol trong chính Object File đó, vì vậy không thể lưu trữ thông tin symbol mà các File khác tham chiếu.
✏️Example: Giả sử một helloworld.c sử dụng hàm printf() trong include <stdio.h>. 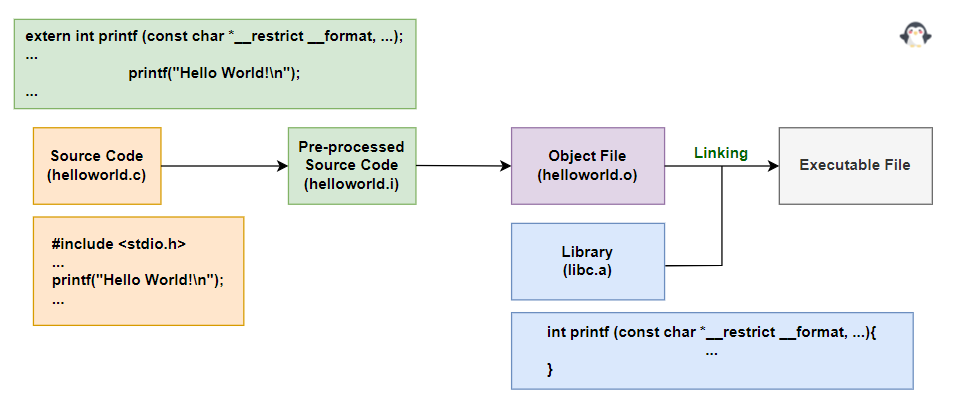 Ví dụ
Ví dụ
Chúng ta có thể biên dịch helloworld.c để tạo ra một tệp đối tượng helloworld.o.
Tuy nhiên, helloworld.o này không thể thực thi độc lập. Bởi vì trong file này không có phần định nghĩa thực sự của hàm printf().
Mặc dù quá trình tiền xử lý đã sao chép nguyên mẫu của hàm printf() từ #include <stdio.h>, nhưng phần định nghĩa của printf() lại không được bao gồm. Như đã nói trong cấu trúc tệp đối tượng (Object File Format), bảng ký hiệu (Symbol table) chỉ chứa thông tin ký hiệu (symbol) của file helloworld.o mà mà không chứa thông tin về hàm printf() vì hàm này được tham chiếu từ bên ngoài.
Nói cách khác, để chạy được helloworld.o, chúng ta cần phải kết nối tệp đối tượng helloworld.o với tệp đối tượng có định nghĩa hàm printf() (thường từ thư viện chuẩn libc.a).
Quá trình kết nối này được gọi là liên kết. Bây giờ, ta sẽ tìm hiểu thêm về nó. 😤😤😤
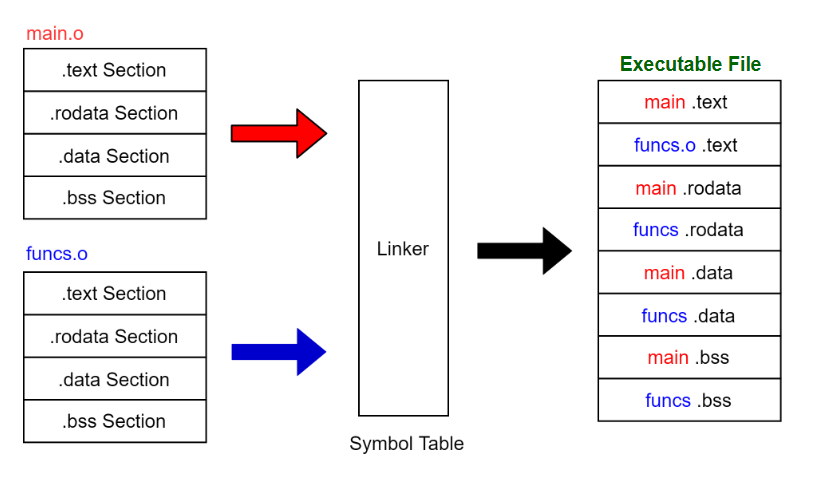
4. Quá trình liên kết (Linking)
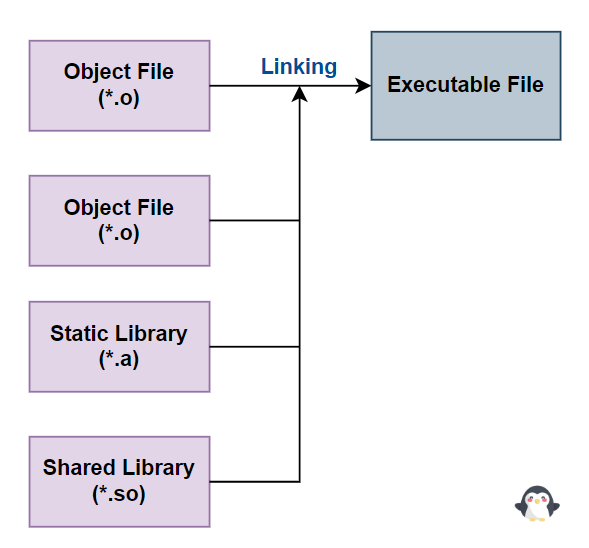 Linking
Linking
Quá trình liên kết là quá trình sử dụng Linker để kết hợp các Object Files (*.o) thành một Executable File.
Trong quá trình này, các Object Files (*.o) và các Library mà chương trình sử dụng sẽ được liên kết lại để tạo thành một tệp thực thi duy nhất.
Tùy thuộc vào cách liên kết thư viện, quá trình này có thể chia thành hai loại:
- Liên kết tĩnh (Static Linking): Các thư viện được kết nối trực tiếp vào tệp thực thi trong quá trình biên dịch.
- Liên kết động (Dynamic Linking): Các thư viện không được liên kết vào tệp thực thi ngay lập tức, mà sẽ được tải và liên kết khi chương trình chạy.
Vai trò
Vai trò của Linking có thể chia thành hai phần chính:
- Symbol Resolution.
- Relocation.
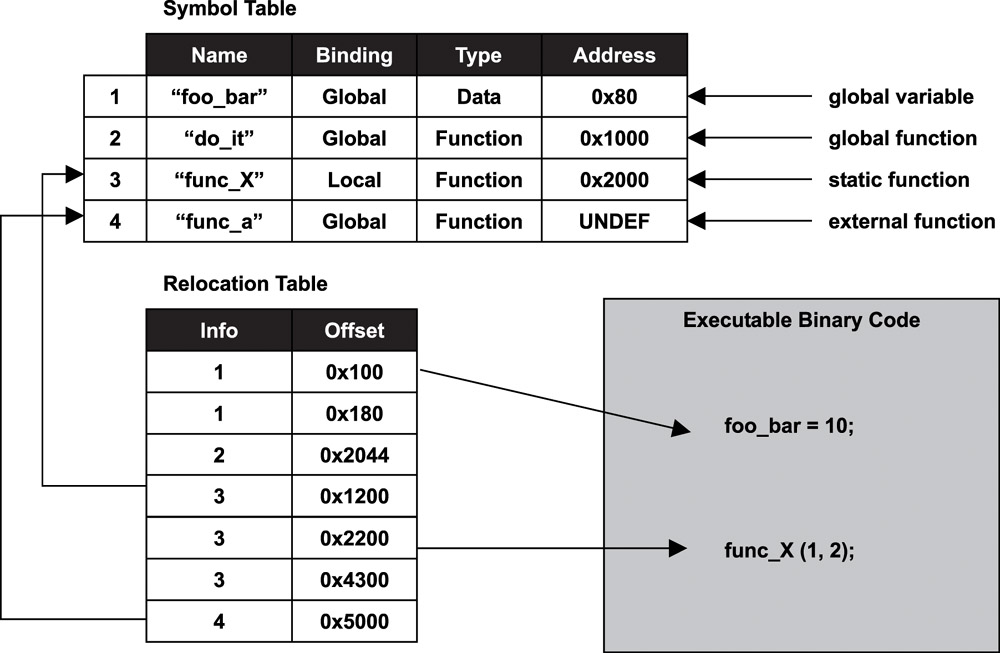
Symbol Resolution
Symbol Resolution là quá trình quyết định cách liên kết các tham chiếu ký hiệu trong các tệp đối tượng với các định nghĩa ký hiệu. Khi nhiều tệp đối tượng chứa các hàm hoặc biến có cùng tên, quá trình này sẽ xác định hàm hoặc biến nào trong tệp nào sẽ được sử dụng.
Relocation
Reallocation là quá trình sắp xếp lại địa chỉ dữ liệu hoặc địa chỉ tham chiếu bộ nhớ của mã trong tệp đối tượng (object file).
Khi liên kết (Linking) các tệp đối tượng mà trình biên dịch đã tạo thành một tệp thực thi duy nhất, địa chỉ dữ liệu hoặc địa chỉ tham chiếu bộ nhớ của mã trong từng tệp đối tượng sẽ khác với địa chỉ trong tệp thực thi kết hợp. Do đó, nó cần phải được sửa đổi sao cho phù hợp.
Để thực hiện điều này, trong tệp đối tượng có một phần chứa thông tin điều chỉnh (Relocation Information Section).
Trong quá trình liên kết, các phần cùng loại được kết hợp lại, và sau đó thực hiện điều chỉnh lại.